Perl, 1994-2011
In 1994, I learnt Perl. It was fantastic. I used it to:
- 1995: Build CCChat – the unofficial IITM email system and software repository
- 1999: Build my entire blog from scratch
- 2000: Author my 2nd year thesis on the Behavioural Aspects of Financial Analysts by analyzing 600MB of IBES data
- 2002: Analyze where to place the central processing hubs for a bank
- 2004: Analyze the interest durations of public sector banks
- 2005: Creating music quizzes
- 2006: Create my own music search engine (which earned me about $100 a month in Google Ad revenue for a while)
- 2006: Automated resume filtering
- 2007: Create custom search engines
- 2008: Build application launchers
In 2006, I was convinced I should stick to Perl over Python.
In 2008, Google launched AppEngine and it provided free hosting (which was a big deal!) but had only 2 runtimes: Java and Python. The choice was clear. I’d rather learn Python than code in Java.
By 2011, I stopped installing Perl on my laptop.
Though most people know me mainly as a Python developer, I’ve programmed in Perl for about as long as I have in Python. I have fond memories of it. But I can’t read any of my code, nor write in it anymore.
When I watched The Perl Conference (now called The Perl and Raku Conference — Perl 6 is called Raku), I was surprised to hear how much the language had declined.
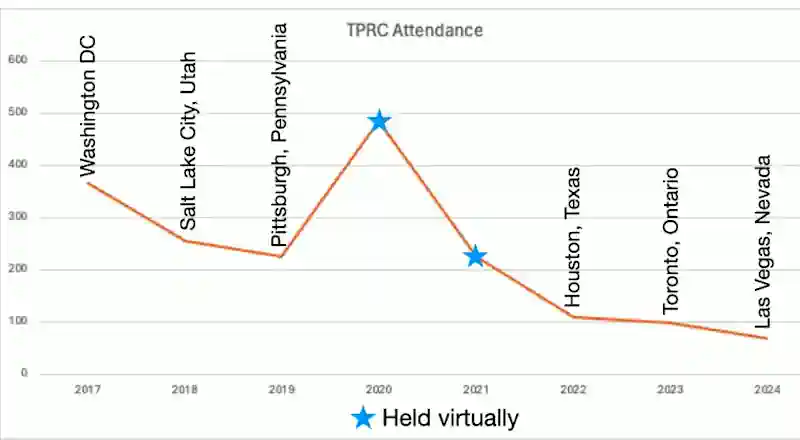
There were fewer than 100 attendees – and for 2025, they’ve decided to go smaller and book a tiny hotel, so as to break-even even if only 20 people show up.
Few languages have had as much of an impact on my life and thinking. My knowledge of modern programming comes from The Camel Book, functional programming from Higher Order Perl, Windows programming from Learning Perl on Win32 Systems, and so on. Even my philosophy of coding was shaped by Larry Wall’s the three great virtues of a programmer.
This is my homage to the language that shaped me. Bless you, Perl!