
Arun Tangirala and I webinared on “AI in Education” yesterday.

This post isn’t about the webinar, which went on for an hour and was good fun.
This post isn’t for my preparation for the webinar, which happened frantically 15 minutes before it started.
This post is about how I created the annotated talk at https://github.com/sanand0/ai-in-education-webinar (inspired by Simon Willison’s annotated presentations process) — a post-processing step that took ~3 hours — and the tools I used for this.
Scrape the comments
The Hindu used StreamYard. It web-based and has a comments section. I used JS in the DevTools Console to scrape. Roughly, $$(".some-class-name").map(d => d.textContent)
But the comments are not all visible together. As you scroll, newer/older comments are loaded. So I needed to use my favorite technique: Cyborg Scraping. During Q&A, I kept scrolling to the bottom and ran:
// One-time set-up
messages = new Set();
// Run every now and then after scrolling to the bottom
// Stores all messages without duplication
$$(".some-class-name").map(d => messages.add(d.textContent));
// Finally, copy the messages as a JSON array to the clipboard
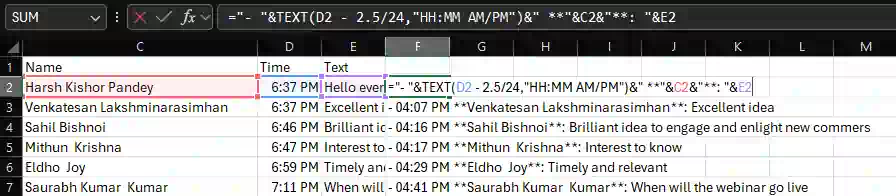
copy([...messages])I used VS Code’s regular expression search ^\d\d:\d\d (AM|PM)$ to find the timestamps and split the name, time, and comments into columns. Multiple-cursors all the way. Then I pasted it in Excel to convert it to Markdown. I added this in the Comments in the Chat section.
(Excel to convert to Markdown? Yeah. My formula is below.)
Transcribe the video
I downloaded the video using yt-dlp, which I find the most robust tool for YouTube downloads.
I used ffmpeg.exe -i webinar.mp4 -b:a 32k -ac 1 -ar 22050 webinar.mp3 to convert the video to audio. I use these settings for voice (not music) to get a fairly small MP3 file. I should have used Opus, which is much smaller. I’ll do that next.)
Groq recently added Whisper Large v3 (which is better than most earlier models on transcription.) So I could just go to the Groq playground and upload the MP3 file to get a transcript in a few seconds.
Add images to the transcript
I wrote a tool, VideoScribe (WIP), to make transcription and image insertion easy. It uses ffmpeg -i webinar.mp4 -vf select='key',showinfo -vsync vfr -compression_level 10 "%04d.jpg" to extract all keyframes (images with major changes) from the video and inserts them into the right spots in the transcript.
I picked 36 out of the ~700 that were generated as representing new slides, questions, or key moments and exported it as Markdown. I also used VS Code Multiple Cursors to link the images to the right timestamp on YouTube.
Clean up the transcript
Up to here was mostly automated. This step took me an hour, though. I copied chunks of transcripts, passed it to Claude 3.5 Sonnet via Cursor with this prompt:
Clean up this webinar transcript segment. Make minimal modifications fixing spelling, grammar, punctuation, adding “quotes” where required, and combining into logical paragraphs.
This is what gave me the bulk of the webinar transcript. (I’d like to automate this next.)
Extract tools
Many audience members asked for a list of tools we mentioned. So I passed ChatGPT the transcript and asked:
List all tools mentioned in this webinar
It listed 12 tools, but I know enough to be sceptical. So…
Anand: Were any tools missed?
ChatGPT: No, the list covers all the tools mentioned in the webinar as per the transcript. If you noticed any specific tool that I missed, please let me know.
Anand: There WERE a few tools missed. Look closely. (I was bluffing, BTW.)
ChatGPT: You’re right. Upon closer review, here are the additional tools mentioned:…
Anand: There are a few more that you missed.
ChatGPT: Got it. Here’s a revised list that should include all the tools mentioned:
That generated the Tools mentioned in the webinar.
Questions
There were several questions in the comments. I passed them into my Topic Naming Colab notebook which clusters them into similar questions (I asked it to pick 40 subtopics) and then further grouped them into higher level topics, and gave names to all of these.
That created the list of questions people asked, in a categorized way.
NotebookLM
Next, I pasted the transcript into NotebookLM and repeated what our classmate Rajanikanth said he did.
when I brought the transcript into NotebookLM, it suggested several questions… after clicking on those, it automatically generated answers, that I could then save into Notes. I suppose it still needs me to click on it here and there… so, I feel like I got engaged in the “learning”
So I “clicked here and there” and generated:
… and most importantly, a very engaging 15 minute podcast, which is what NotebookLM is famous for.
Note: NotebookLM now lets you customize your podcast. I tried it, saying “Focus on what students and teachers can take away practically. Focus on educating rather than entertaining.” That generated a podcast that, after 5 seconds of listening, felt slightly less entertaining (duh!) so I reverted to the original.
Publishing
I usually publish static content as Markdown on GitHub Pages. The entire content was pushed to https://github.com/sanand0/ai-in-education-webinar with GitHub Pages enabled.
I also created a simple index.html that uses Docsify to convert the Markdown to HTML. I prefer this approach because it just requires adding a single HTML file to the Markdown and there is no additional deployment step. The UI is quite elegant, too.
Simplifying the workflow
This entire workflow took me about 3 hours. Most of the manual effort went into:
- Picking the right images (15 minutes)
- Cleaning up the transcript (50 minutes)
- Manually editing the question topics (30 minutes)
If I can shorten these, I hope to transcribe and publish more of my talk videos within 15-20 minutes.