text-embedding-ada-002 used to give high cosine similarity between texts. I used to consider 85% a reasonable threshold for similarity. I almost never got a similarity less than 50%.
text-embedding-3-small and text-embedding-3-large give much lower cosine similarities between texts.
For example, take these 5 words: “apple”, “orange”, “Facebook”, “Jamaica”, “Australia”. Here is the similarity between every pair of words across the 3 models:
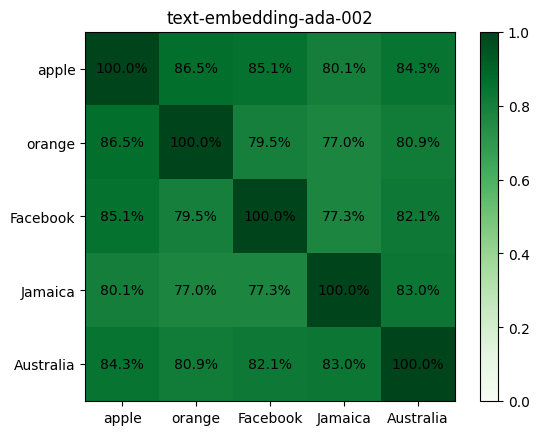
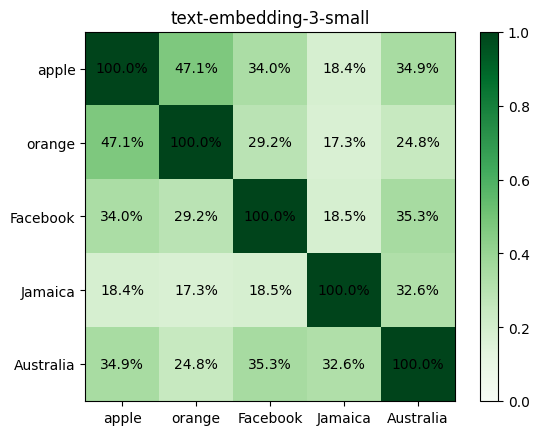
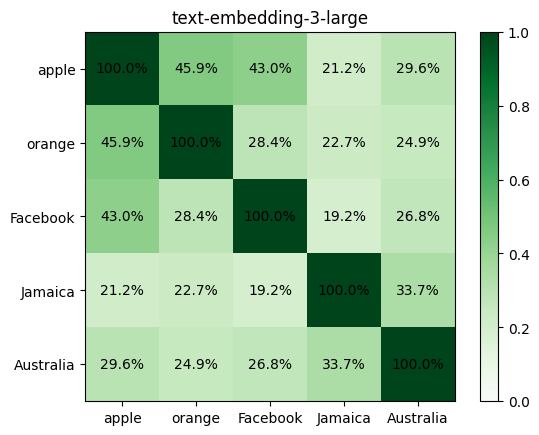
For our words, new text-embedding-3-* models have an average similarity of ~43% while the older text-embedding-ada-002 model had ~85%.
Today, I would use 45% as a reasonable threshold for similarity with the newer models. For example, “apple” and “orange” have a similarity of 45-47% while Jamaica and apple have a ~20% similarity.
Here’s a notebook with these calculations. Hope that gives you a feel to calibrate similarity thresholds.
Pingback: The LLM Psychologist - S Anand