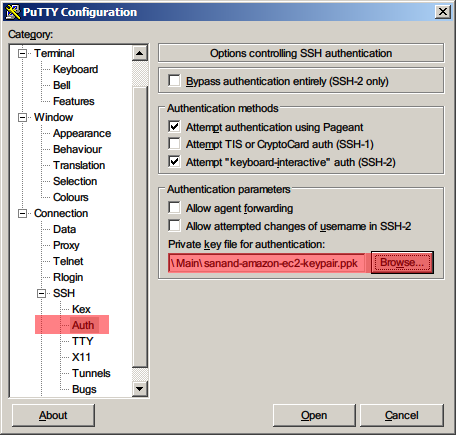
Last month, my first application went live.
I’ve been writing code for 20 years. Not one line of my code has been officially deployed in a corporate. (Loser…)
It’s a happy feeling. Someone defined happiness as the intersection of pleasure and meaning. Writing code is pleasurable. Others using it is meaningful.
But this post isn’t quite about that. It’s about the hoops I’ve had to jump through to make this happen.
I’ve been living in a nightmare since March 2009. That was when I decided that I’d try and get corporates to use open source.
March 2009
It began with a pitch to a VC firm. They were looking to build a content management system (CMS). Normally we’d pull together slides that say we’ll deliver the moon. This time, we put together demo based on WordPress’ CMS plugins.
The meeting went fabulously well. We said, “Here’s a demo we’ve built for you. Do you like it?” The business lead (Stuart) was drooling and declared that that’s exactly what they wanted. The IT lead (another Stuart) was happy too, but warned the business users: “Just remember: this isn’t how we do development, so don’t get your hopes up that we can deliver stuff like this :-)”
Time to make my point. I asked, “What’s your policy on open source software?”
The business lead went quiet. “I don’t know,” he finally said. Fair enough.
I turned to the IT lead. “Well, we don’t use it as a matter of policy… there are security concerns…” he said.
“Which web server do you use?”
”Oh, OK. I see what you mean. We use Apache. So on a case to case basis, we have exceptions. But generally we have security concerns.“
”Why? Do you believe open source software is more insecure than commercial software?“
He thought about it for a while. “Well… maybe. I don’t know.” We debated this a bit. Then we found the real issue: “It’s just that we don’t have control over the process. We don’t know enough about it to decide.”
A couple of weeks later, I tried pitching to a newspaper company. This time, it was our sales team that raised the same question. “But… isn’t open source insecure?”
I didn’t even bother pitching any open source stuff to them. But I’d learnt my lessons:
1. Demo the application. Don’t talk about it.
2. Show it to the business first, and then tackle IT.
Aside: June 2009
In June, I got another chance. I was building the website for a large retailer. The very first thing I did was ask to see the Javascript. Total mess, and filled with browser-incompatible DOM requests. So I went over to their web development team.
“Look, why don’t you guys use a Javascript library? It’ll get you cross browser compatibility and compact maintainable code at the same time.”
And, to their credit, they said, “Sure. Which library?”
I showed them this comparison of jQuery (blue), dojo, scriptaculous and mootools…

… and we agreed on jQuery. So, if nothing else, I’ve managed to get one open source library into a corporate.
July 2009
I was also looking at payments, and retailer was looking to replace their chargeback application. Since I had a week off, I built a working PCI compliant prototype on Django. This time, I applied the lessons I’d learned, and demo-ed it to the business, who were thrilled. Time to tackle IT.
I started with the architecture team. Matt on the architecture team was the most approachable. So I went over, demo-ed it, and said, “Matt, this took a week to put together. It’s based on some new technologies. Are you game to try these out?”
He was. And quite enthused about it too. So we put together a proposal for the architecture review board, proposing a new technology stack: Django / Python and MySQL. As before, I showed the demo before I talked technology. I had prepared answers to all security related questions upfront (and practically memorised section 3 of the PCI guidelines.) The clincher, though, was the business case. To build it on Java, it would cost ~1,000 person days. On Django, I’d mostly done it in 5. There was no way of justifying 1,000 person days for an application that could save, at best £100,000 a year.
So they said “Go ahead, we’re fine if operations and infrastructure are fine.”
It was time to find a Django developer in Infosys. I hunted for a couple of weeks but none was available. (Only 2 people knew Django in the first place.) So that effort got canned, and we were back to the 1,000 person day solution. (Which got canned too, later.)
But in the process, I’d learned my third lesson.
3. If you’re trying new technologies, plan on delivering it yourself.
October 2009
Another application popped up that looked like a prime candidate for introducing open source. They were using an Excel application to fraud screen orders, and wanted to make a web app out of it.
I followed the same route as before. Demo it. Show it to business first, then IT. Built it myself. I skipped Architecture, since they’d already approved the technology stack, and took it straight to Infrastructure.
“This application uses Apache as the web server, MySQL as the database, and uses PHP and Javascript for the application logic. Could we get a Linux server to host it?”
Our entire conversation lasted 30 seconds. He said, “No. We use Windows servers” (I was fine)
“… and you’ll need to chance Apache to IIS” (fine again)
“… and we don’t support PHP, so it’ll have to be Java or .NET” (I don’t know .NET or Java… but fine)
“… and we don’t support MySQL, it’ll have to be SQL Server” (fine, I guess)
“… and we don’t have DBAs available until January, so you’ll have to wait.” (definitely not good.)
So back to the drawing board on the technology stack. I needed something in Java (I know very little Java, but nothing at all in .NET) and to avoid the DBA headache, it would have to bundle in a database. I first explored key-value stores like CouchDB, Redis, etc. None of them worked on Java. The only one I found that did was Persevere, and it was a JSON data store, which fit perfectly with my plans.
By this time, I’d also learn my my fourth and most important lesson.
4. Don’t try to promote open source. Just deliver the application
I said, “This is a custom-built application that runs on Java. Could we get a Windows server to host it?”
The answer was “Yes”, and we had it the next day.
PS: December 2009
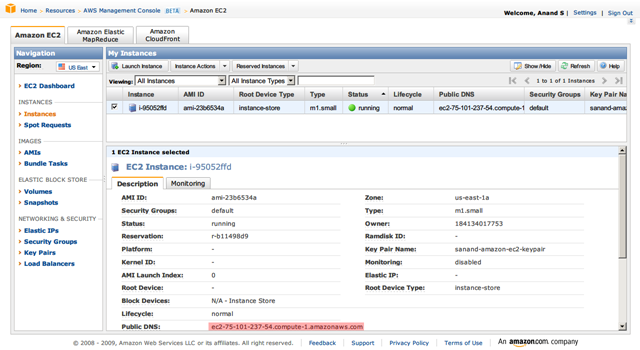
The application’s deployed and running. It has about 10,000 orders fraud screened by now.
And the lessons are well learnt. So when some came over asking if there was any image resizing solution I knew off, I said: “Sure, who’s your business sponsor?” Then I went over and said, “Let me show you this open source application called ImageMagick. It handles aspect ratios correctly, and can crop too. Doesn’t this look professional?” Then I went over to IT and said, “It’s open source, so you can change it. It has Java bindings, so you can integrate it into your environment. It can handle 8 3000×2400 images a second on my puny laptop. It’s used by your competitors. And I can build it for you if you like.”
I might just have my second open source entry into a corporate this year.