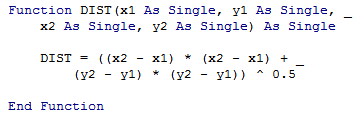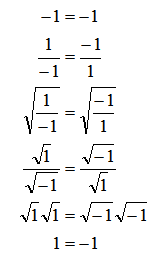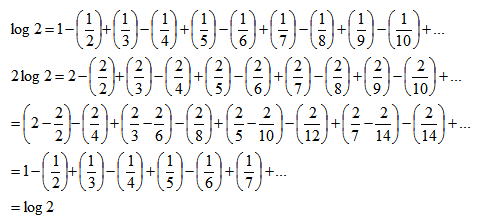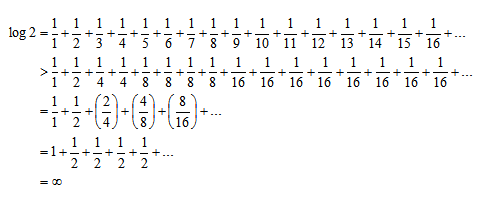User-defined functions to get cell formatting
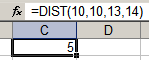
Sometimes you want to check the colour of a cell, or whether a cell is bold. This can be easily done with user-defined functions (UDFs). (To create a UDF, press Alt-F11, Alt-I-M, and type the code below.)

You can use ISBOLD(cell) to check if a cell is bold, and BGCOLOR(cell) to get the background colour of the cell. This lets you selectively process bold or shaded cells. The two examples below show how you can add only the cells in bold, or only the shaded cells.
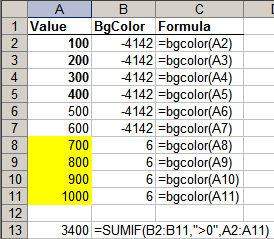
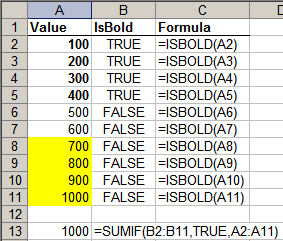
Rather than use an additional column for ISBOLD or BGCOLOR, you can use an array formula, like below. (Remember to press Ctrl-Shift-Enter instead of Enter after typing this formula)
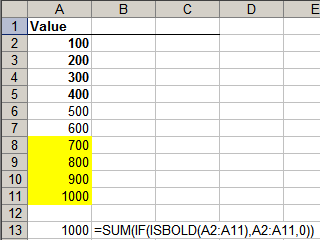
But first, you need to change the UDF to return an array rather than a single value. So IsBold will have to be modified as shown.
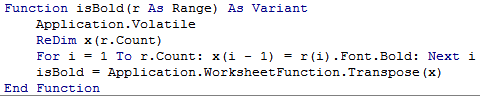
User-defined functions that process arrays can be very powerful. It can bring the full power of functional programming into Excel. I’ll describe some next week.
PS: In case you’re wondering, Application.Volatile tells Excel to recalculate the function every time the worksheet is recalculated. When a cell is made bold, or shaded, the value of the cell doesn’t change. So Excel doesn’t recalculate any formulas. You’ll have to manually press F9 every time to recalculate these cells. And Application.Volatile ensures that when you press F9, these functions are recalculated.
User-defined functions to get cell formatting Read More »