The World Mosquito Program (WMP) modifies mosquitoes with a bacteria — Wolbachia. This reduces their ability to carry deadly viruses. (It makes me perversely happy that we’re infecting mosquitoes now 😉.)
Modifying mosquitoes is an expensive process. With a limited set of “good mosquitoes”, it is critical to find the best release points that will help them replicate rapidly.
But planning the release points took weeks of manual effort. It involved ground personnel going through several iterations.
So our team took high-resolution satellite images, figured out the building density, estimated population density based on that, and generated a release plan. This model is 70% more accurate and reduced the time from 3 weeks to 2 hours.
Some actors form cliques — working only with each other
Often, comedians are the bridge between cliques
It’s interesting to see how actors from one clique can connect to another
Creating the storyline
When exploring of actors’ connections, we found a clearly delineated network structure.
The group of densely clustered actors is the Bollywood-Tollywood-Mollywood-Kollywood nexus. It appears disconnected from the Hollywood cluster. (We excluded anyone who hadn’t acted together in at least 4 films.)
We realized that it’s tough for someone in Bollywood to connect to Hollywood. Maybe that could be the plot? For example, what if Amitabh Bachchan wants to act with Metryl Streep?
But this isn’t an interesting story. So we asked:
Who is the most desirable heroine in Hollywood? Our guess was Angelina Jolie
The morning of the hackathon was spent finalizing the screenplay and dialogues, written on Dropbox Paper.
CUT TO:
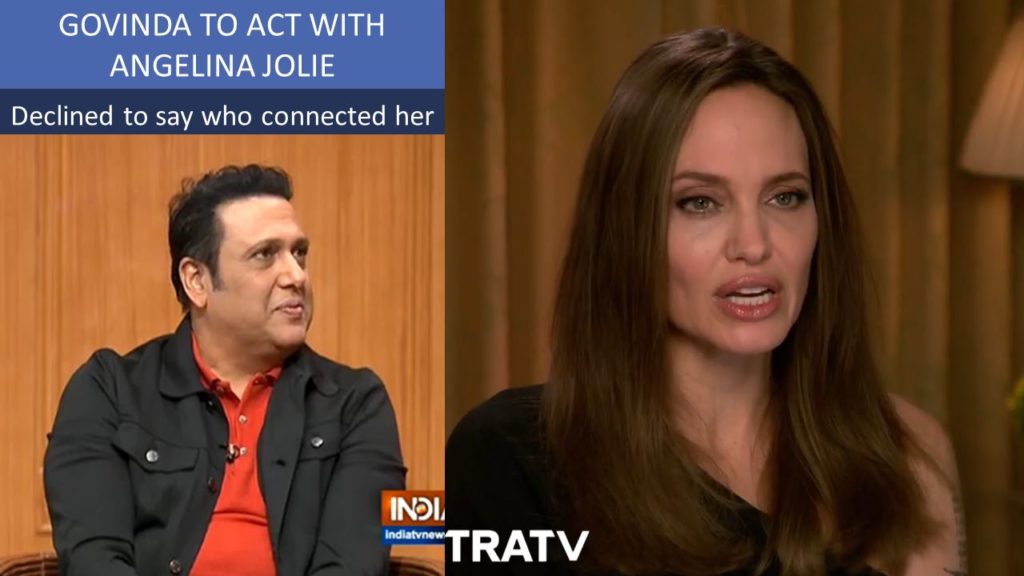
- Video of Govinda "declining James Cameron's Avatar" on Aap Ki Adalat
- Niyas: On July 29, 2019, Govinda announces he declined a role in Avatar.
- Video: https://youtu.be/NyFF18a7e-Y
- Picture: https://twitter.com/mohan_rajkeshav/status/1156148768049262592
CUT TO:
- Visual: Show an interview video of Govinda and of Angelina
- Niyas: Today, he announced his next film with Angelina Jolie.
A “close friend” connected them, but didn't say who.
- Kishore: Who is this close friend? Why is he not naming them?
- Video: https://youtu.be/NyFF18a7e-Y (Govinda)
- Video: https://youtu.be/JNrH1W7aKc8 (Angelina)
CUT TO:
- Visual: Show the top 8 heroines Govinda has acted with.
Visualize this data with animation.
One option is to have Govinda’s pic in the center,
and have each of these 9 heroine’s images appear around him
as a circle, with the number of pictures in a link.
Or as the inverse link distance (e.g. 11 is closest)
11 Neelam Kothari
10 Kimi Katkar
10 Karisma Kapoor
9 Raveena Tandon
9 Farha Naaz
8 Juhi Chawla
6 Anita Raj
6 Mandakini
5 Shilpa Shetty Kundra
- Niyas: Maybe it’s because it’s one of his heroines?
He’s mostly acted with Neelam, Kimi and Karishma.
But none of them has acted with any Hollywood actor.
MORPH TO:
- Visual: Add these actors with pics to the same visual,
but clearly differentiated by gender. Also add their names.
22 Shakti Kapoor
18 Kader Khan
13 Gulshan Grover
9 Anupam Kher
8 Dharmendra
7 Johnny Lever
6 Sadashiv Amrapurkar
6 Vikas Anand
6 Sanjay Dutt
6 Prem Chopra
6 Asrani
- Kishore: So maybe this “close friend” is a male actor?
- Niyas: He’s acted with Gulshan Grover, Kader Khan and Shakti Kapoor a lot.
- Kishore: Shakti Kapoor is practically his boyfriend!
MORPH TO:
- Visual: Zoom into Gulshan Grover and Anupam Kher.
Build a network of film posters around them
with their Hollywood films (max 2-4)
- Anupam Kher
- Bend It Like Beckham
- Lust & Caution
- Silver Linings Playbook
- A Family Man
- Gulshan Grover
- Prisoners of the Sun
- The Second Jungle Book
- Marigold
- Monsoon
- Niyas: Gulshan Grover and Anupam Kher have acted in a number of Hollywood films
- Kishore: But have they acted with Angelina Jolie?
- Niyas: No, never with Angelina Jolie.
- Kishore: But what if any of them connected him to someone who connected him to Angelina?
CUT TO:
- Visual: Show Angelina Jolie with ~100 actors around her. Highlight the following:
- Jack Black, 3
- Dustin Hoffman, 3
- Giovanni Ribisi, 2
- Robert De Niro, 2
- Brad Pitt, 2
- Elle Fanning, 2
- Bryan Cranston, 2
- 92 other actors with only 1 film each
- Highlight Irrfan Khan — A Mighty Heart
- Niyas: Angelina Jolie has acted with less than 100 actors.
Dustin Hoffman and Jack Black, mostly.
Only one of them is an Indian actor: Irrfan Khan
MORPH TO:
- Visual: Expand the connection between Angelina and Irrfan
- Kishore: So, Govinda needs to connect to Irrfan Khan somehow.
MORPH TO:
- Visual: Connect Govinda to Irrfan Khan via
- Gulshan Grover via Knock Out
- Sanjay Dutt via Knock Out
- Tabu via Saajan Chale Sasural, Dil Ne Phir Yaad Kiya (and 2 others)
- Niyas: That should be easy.
Gulshan Grover and Irrfan Khan have acted together in Knock Out.
So has Sanjay Dutt.
But Tabu will be a better option. Govinda and Irrfan Khan have acted with her in 4 movies each.
MORPH TO:
- Visual: Show path from Govinda to Tabu to Irrfan to Angelina.
- Kishore: Then, Govinda must have connected to Tabu
who introduced him to Irrfan Khan,
who in turn connected him with Angelina Jolie.
Create the video
Anand and Niyas created the visuals on PowerPoint, collaborating on Dropbox.
Ganes and I created a data movie on speed-cubing records as part of a Gramener hackathon.
Here’s a video of us talking about how we created it.
Anand: We picked the Rubik’s cube story for this hackathon. Tell me more about how this excited you.
Ganes: Since my son started solving the Rubik’s cube a few months back, I’ve been fascinated with these competitions. I still don’t know how to solve it, but I like watching it.
Anand: But he does?
Ganes: Yeah, he does. So, in the competitions, I’ve seen kids solving the Rubik’s cube in under 10 seconds. So that was the first source of amazement. I’ve seen kids doing it with one hand, blindfolded. I first couldn’t believe it. Doing it with their legs. So that got me really interested.
When we were talking about this, and I was sharing my amazement, we were talking about the hackathon and the conversations kind of merged. So that, I think, the curiosity around it led to picking this as the story.
Anand: And what was the next step?
Ganes: I have always seen the World Cube Association publishing these records. Their website is great. So I thought maybe we could scrape from that, and that’s when I start looking at the website and the competitions we can pick. and then I stumbled on the export feature where they have multiple formats neatly curated that you can take and directly start the analysis.
Anand: Which was actually a big factor in deciding to go for this. Big data set. Very rich, interesting possibilities.
Ganes: So we had had some five or six ideas. This immediately shot up to the top. So after we got the idea, you kind of took over. I think after I mentioned that all these formats were available, it got you excited. So what did you do after that?
Anand: Then it became a question of what all interesting things we can find. It’s almost an exploratory data analysis, but my approach to EDA (exploratory data analysis) is: let’s formulate the hypotheses and then validate, and see if there Is an interesting story behind it.
So it begins with, for instance, the speed at which records have been broken. Today, it’s at 3½ seconds. We know that. But how fast did it fall? Or: what’s the spread of solving-speed for somebody who solves it fast? Does the same person solve it really fast sometimes and really slow sometimes? Is there a movement in their average? You said, “Let’s see how much longer it takes to solve bigger cubes.” Nikhil was going to take the demographics of solvers and see how they’re spread out. There are definitely a lot of Chinese solves in the spread. So, the thing was, let’s look at possible ideas that could lead to an interesting answer, and then validate those.
Ganes: It was almost like “What would we be interested in finding out” and not necessarily like looking at the column of data.
Anand: Yes. And that I think is important, because, from the data, there may be some ideas. But after absorbing it, knowing what’s interesting is what should drive the story.
Ganes: Right. Yeah. So that was a good starting point. We listed all of these on the board. Then, what did you do next?
Anand: Then it’s about proving these. So, we know here are some possible interesting stories, and let us explore and validate whether these are, in fact, interesting, or can be turned into something interesting. So, when I looked at the speed at which records were broken, for instance, I thought that would be an interesting story. But it wasn’t. It was just getting broken at a steadily successive pace.
But something that I did not expect emerged, which is that Wusheng Du, who holds the world record, is not the person who was there in the records consistently. In fact, Felix Zemdegs has been the consistent winner for the last 10 years and is the only cubing champion who’s won the WCA twice. So, that was something that emerged from doing the analysis. So, that has the ability, therefore, of both proving what we’re looking to prove (or disproving), and also coming up with new stuff that we can choose to incorporate into the story.
Ganes: Almost like starting with a business hypothesis, or what, in the enterprise world, the business wants to know, and then once you get into the data, the data is revealing a few interesting insights, and then you kind of marry both. Looks just like that.
Anand: Exactly. Exactly.
Ganes: So, we identified the insights. And then, the target here was to come up with a 2 minute video. So how did you plan from insights to the video.
Anand: So, one of my cousins is a director, and she tried explaining to me the concept of a screenplay. I never really understood it, even though I’ve read a number of screenplays. So, in the last hackathon, when I was creating a (data) movie, that’s when I realised: as I started writing what I want to shoot (because it requires a whole lot of planning), I was effectively writing a screenplay.
The steps are, basically, you have to decide what are the frames or the sequences you want to shoot. So, one sequence was: we want to introduce this Rubik’s cube win. Another sequence was: we want to show how quickly different types of cubes can be solved, etc.
So, for each of these, what I do is: create a storyline that has the following structure. One: what is the message I want people to take away from that.
Ganes: The headline from there.
Anand: Exactly.
And then, in order to do that, what are the words I would narrate on top of it? That literally forms the dialogue. The third thing is, what are the visuals that prove the dialogue. That I structure in the form of a video. The fourth thing is the transition — from one video to another, or from one sequence to another, how do I flow. These are the 4 things that I captured.
When I write down the full dialogue. I speak it out, put in a timer, and then say “OK, this took 10 seconds, this took 15 seconds, this took 14 seconds” and so on.
Then comes the process of recording (the audio). Assembling the visuals, yes, but timing it and sequencing it based on the recording is pretty critical. So, actually, I wanted your voice – it’s better. And initially, I wanted you to do the recording, but because you were busy in the Dell workshop, I had to do the recording to make sure that I get the timing. Then you re-recorded post that.
That recording makes a huge difference. The audio quality on my iPhone is better than the laptop. I transfer it via Dropbox on to the system.
Ganes: Were there some issues because you have some insights and you have a certain sequence, but it may not add up to 2 minutes. Or, there might be something which will just not flow. How do you correct those issues?
Anand: I found that I consistently underestimate (the time). I thought that we only have material for 1½ minutes, but I knew at that point that invariably, because of this bloat, it will somehow add up to 2 minutes. Which is exactly what happened. It moved to 2 minutes 4 seconds.
Ganes: Yes. Exactly. Yeah.
Anand: So, once you’ve done it once or twice, that amount of correction is there. It’s in fact a whole lot easier to control a video than something as crazy as a (software) program, for instance. The estimation error in programming is much higher than this.
The good part is that post production or editing can take care of a lot of stuff. That 2-minute video can be cut to 1½ if required.
Ganes: Yeah, it can be improved, but my biggest fear is: after recording, the post production is a nightmare. It takes hours and hours of effort. A five-minute video, to post, probably takes 2 hours.
Anand: That is true.
Ganes: How do you go about it? After having these audio clippings, videos and images, how do you stitch all together into a video?
PowerPoint makes it fairly simple. I can put in an audio in the background. I can handle the animations. It’s not a great tool at all, but it’s a tool I’m very familiar with. So, my workflow is: one slide is one shot or one headline in the storyline. Then I record the video independently or download it from YouTube, put it in the background or wherever. Create all the visuals, create the animations around it, put it there. At this point, the raw material is in. Then I insert the audio and let it play the background for that particular slide. Then I time the animation to the audio.
This is a slow process because PowerPoint doesn’t have the right tools. So I play the audio till that point and then set the animation. Then I start from the beginning again, play the audio to the next point, and then set that animation. Which takes a long duration. But once that’s sorted out, I play that full slide and it works out, I then go back and correct.
The good part is that the audio is the time keeper. I pre-recorded the audio. So I know that the entire duration is only going to be 1.8 minutes (and then towards the end we added a few more vidoes that took it to 2 minutes). So the audio keeps you in control, and if you synchronize everything to the audio, then it becomes easier.
Then I exported it into a video file from PowerPoint directly, and then did a little bit of post-processing, adding a background music and adding a few captions, mostly, on Windows Video Editor, and then gave it to you. Which was at around 9 o’clock or so. What did you do from 9 o’clock to 3 o’clock?
Ganes: So, the first thing — on the PowerPoint, I couldn’t believe that you’d done all this on PowerPoint. Yes, you’re taking the tool beyond the limit it was designed for.
I’ve been working with iMovie for a year, and I find it very powerful. For someone who doesn’t come from that background, it was very easy for me to pick up. I had the images and raw video footage for the different portions we were trying to introduce. I was able to split the audio that you recorded from the video, and then was able to record mine and add it. iMovie has these multiple streams you can insert and remove. I had one stream for my audio for my voice over. And there was this video which you had.
On top of that, I could overlay the pictures and other videos that I had towards the end — two videos playing side-by-side. So all of that was possible. and then I could also introduce background music at the very end. iMovie makes it very easy to move all of these things around. And even the synchronization issue which you told about, that’s much easier to resolve in iMovie.
So, all of this finally coming together, I think, at 3 o’clock… when I had all of this, at 3 o’clock I was hunting for the background music (laughs). I was playing all kinds of clips and finally I chose one. So that’s how we got the final YouTube video.
Anand: My lesson from this is: make sure you have a team member who has a Mac!
Ganes: Right, yeah. So let’s go back and look at our video and see what we can learn from it. Thank you!
Minecraft lets you connect to a websocket server when you’re in a game. The server can receive and send any commands. This lets you build a bot that you can … (well, I don’t know what it can do, let’s explore.)
Minecraft has commands you can type on a chat window. For example, type / to start a command and type setblock ~1 ~0 ~0 grass changes the block 1 north of you into grass. (~ means relative to you. Coordinates are specified as X, Y and Z.)
Note: These instructions were tested on Minecraft Bedrock 1.16. I haven’t tested them on the Java Edition.
Connect to Minecraft
You can send any command to Minecraft from a websocket server. Let’s use JavaScript for this.
First, run npm install ws uuid. (We need ws for websockets and uuid to generate unique IDs.)
const WebSocket = require('ws')
const uuid = require('uuid') // For later use
// Create a new websocket server on port 3000
console.log('Ready. On MineCraft chat, type /connect localhost:3000')
const wss = new WebSocket.Server({ port: 3000 })
// On Minecraft, when you type "/connect localhost:3000" it creates a connection
wss.on('connection', socket => {
console.log('Connected')
})
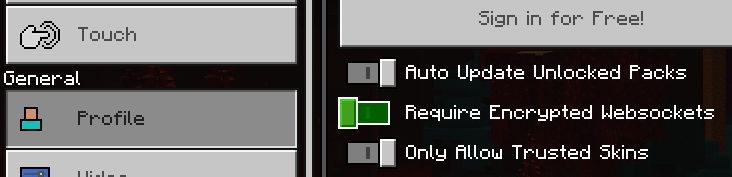
On Minecraft > Settings > General > Profile, turn off the “Require Encrypted Websockets” setting.
Run node mineserver1.js. Then type /connect localhost:3000 in a Minecraft chat window. You’ll see 2 things:
MineCraft says “Connection established to server: ws://localhost:3000”
Node prints “Connected”
Now, our program is connected to Minecraft, and can send/receive messages.
Notes:
The Python equivalent is in mineserver1.py. Run python mineserver1.py.
If you get an Uncaught Error: Cannot find module 'ws', make sure you ran npm install ws uuid.
If you get an “Encrypted Session Required” error, make sure you turned off the “Require Encrypted Websockets” setting mentioned above.
To disconnect, run /connect off
Subscribe to chat messages
Now let’s listen to the players’ chat.
A connected websocket server can send a “subscribe” message to Minecraft saying it wants to “listen” to specific actions. For example, you can subscribe to “PlayerMessage”. Whenever a player sents a chat message, Minecraft will notify the websocket client.
Here’s how to do that. Add this code in the wss.on('connection', socket => { ... }) function.
// Tell Minecraft to send all chat messages. Required once after Minecraft starts
socket.send(JSON.stringify({
"header": {
"version": 1, // We're using the version 1 message protocol
"requestId": uuid.v4(), // A unique ID for the request
"messageType": "commandRequest", // This is a request ...
"messagePurpose": "subscribe" // ... to subscribe to ...
},
"body": {
"eventName": "PlayerMessage" // ... all player messages.
},
}))
Now, every time a player types something in the chat window, the socket will receive it. Add this code below the above code:
// When MineCraft sends a message (e.g. on player chat), print it.
socket.on('message', packet => {
const msg = JSON.parse(packet)
console.log(msg)
})
This code parses all the messages it receives and prints them.
This code in is mineserver2.js. Run node mineserver2.js. Then type /connect localhost:3000 in a Minecraft chat window. Then type a message (e.g. “alpha”) in the chat window. You’ll see a message like this in the console.
{
header: {
messagePurpose: 'event', // This is an event
requestId: '00000000-0000-0000-0000-000000000000',
version: 1 // using version 1 message protocol
},
body: {
eventName: 'PlayerMessage',
measurements: null,
properties: {
AccountType: 1,
ActiveSessionID: 'e0afde71-9a15-401b-ba38-82c64a94048d',
AppSessionID: 'b2f5dddc-2a2d-4ec1-bf7b-578038967f9a',
Biome: 1, // Plains Biome. https://minecraft.gamepedia.com/Biome
Build: '1.16.201', // That's my build
BuildNum: '5131175',
BuildPlat: 7,
Cheevos: false,
ClientId: 'fcaa9859-0921-348e-bc7c-1c91b72ccec1',
CurrentNumDevices: 1,
DeviceSessionId: 'b2f5dddc-2a2d-4ec1-bf7b-578038967f9a',
Difficulty: 'NORMAL', // I'm playing on normal difficulty
Dim: 0,
GlobalMultiplayerCorrelationId: '91967b8c-01c6-4708-8a31-f111ddaa8174',
Message: 'alpha', // This is the message I typed
MessageType: 'chat', // It's of type chat
Mode: 1,
NetworkType: 0,
Plat: 'Win 10.0.19041.1',
PlayerGameMode: 1, // Creative. https://minecraft.gamepedia.com/Commands/gamemode
Sender: 'Anand', // That's me.
Seq: 497,
WorldFeature: 0,
WorldSessionId: '8c9b4d3b-7118-4324-ba32-c357c709d682',
editionType: 'win10',
isTrial: 0,
locale: 'en_IN',
vrMode: false
}
}
}
Notes:
The Python equivalent is in mineserver2.py. Run python mineserver2.py.
The full list of things we can subscribe to is undocumented, but @jocopa3 has reverse-engineered a list of messages we can subscribe to, and they’re somewhat meaningful.
Let’s create a pyramid of size 10 around us when we type pyramid 10 in the chat window.
The first step is to check if the player sent a chat message like pyramid 10 (or another number). Add this code below the above code:
// When MineCraft sends a message (e.g. on player chat), act on it.
socket.on('message', packet => {
const msg = JSON.parse(packet)
// If this is a chat window
if (msg.body.eventName === 'PlayerMessage') {
// ... and it's like "pyramid 10" (or some number), draw a pyramid
const match = msg.body.properties.Message.match(/^pyramid (\d+)/i)
if (match)
draw_pyramid(+match[1])
}
})
If the user types “pyramid 3” on the chat window, draw_pyramid(3) is called.
In draw_pyramid(), let’s send commands to build a pyramid. To send a command, we need to create a JSON with the command (e.g. setblock ~1 ~0 ~0 grass). Add this code below the above code:
function send(cmd) {
const msg = {
"header": {
"version": 1,
"requestId": uuid.v4(), // Send unique ID each time
"messagePurpose": "commandRequest",
"messageType": "commandRequest"
},
"body": {
"version": 1, // TODO: Needed?
"commandLine": cmd, // Define the command
"origin": {
"type": "player" // Message comes from player
}
}
}
socket.send(JSON.stringify(msg)) // Send the JSON string
}
Let’s write draw_pyramid() to create a pyramid using glowstone by adding this code below the above code:
// Draw a pyramid of size "size" around the player.
function draw_pyramid(size) {
// y is the height of the pyramid. Start with y=0, and keep building up
for (let y = 0; y < size + 1; y++) {
// At the specified y, place blocks in a rectangle of size "side"
let side = size - y;
for (let x = -side; x < side + 1; x++) {
send(`setblock ~${x} ~${y} ~${-side} glowstone`)
send(`setblock ~${x} ~${y} ~${+side} glowstone`)
send(`setblock ~${-side} ~${y} ~${x} glowstone`)
send(`setblock ~${+side} ~${y} ~${x} glowstone`)
}
}
}
Then type /connect localhost:3000 in a Minecraft chat window.
Then type pyramid 3 in the chat window.
You’ll be surrounded by a glowstone pyramid, and the console will show every command response.
Notes on common error messages:
The block couldn't be placed (-2147352576): The same block was already at that location.
Syntax error: Unexpected "xxx": at "~0 ~9 ~-1 >>xxx<<" (-2147483648): You gave wrong arguments to the command.
Too many commands have been requested, wait for one to be done (-2147418109): Minecraft only allows 100 commands can be executed without waiting for their response.
Typing “pyramid 3” works just fine. But try “pyramid 5” and your pyramid is incomplete.
That’s because Minecraft only allows up to 100 messages in its queue. On the 101st message, you get a Too many commands have been requested, wait for one to be done error.
{
"header": {
"version": 1,
"messagePurpose": "error",
"requestId": "a5051664-e9f4-4f9f-96b8-a56b5783117b"
},
"body": {
"statusCode": -2147418109,
"statusMessage": "Too many commands have been requested, wait for one to be done"
}
}
So let’s modify send() to add to a queue and send in batches. We’ll create two queues:
const sendQueue = [] // Queue of commands to be sent
const awaitedQueue = {} // Queue of responses awaited from Minecraft
In wss.on('connection', ...), when Minecraft completes a command, we’ll remove it from the awaitedQueue. If the command has an error, we’ll report it.
// If we get a command response
if (msg.header.messagePurpose == 'commandResponse') {
// ... and it's for an awaited command
if (msg.header.requestId in awaitedQueue) {
// Print errors 5(if any)
if (msg.body.statusCode < 0)
console.log(awaitedQueue[msg.header.requestId].body.commandLine, msg.body.statusMessage)
// ... and delete it from the awaited queue
delete awaitedQueue[msg.header.requestId]
}
}
// Now, we've cleared all completed commands from the awaitedQueue.
Once we’ve processed Minecraft’s response, we’ll send pending messages from sendQueue, upto 100 and add them to the awaitedQueue.
// We can send new commands from the sendQueue -- up to a maximum of 100.
let count = Math.min(100 - Object.keys(awaitedQueue).length, sendQueue.length)
for (let i = 0; i < count; i++) {
// Each time, send the first command in sendQueue, and add it to the awaitedQueue
let command = sendQueue.shift()
socket.send(JSON.stringify(command))
awaitedQueue[command.header.requestId] = command
}
// Now we've sent as many commands as we can. Wait till the next PlayerMessage/commandResponse
Finally, in function send(), instead of socket.send(JSON.stringify(msg)), we use sendQueue.push(msg) to add the message to the queue.
I walked ~11 million steps in the last 3 years, at ~10K steps daily.
Since 1 Jan 2018, I’ve steadily increased my walking average until Aug 2018. Then my legs started aching. So I cut it down until Jan 2019. In Feb, I resumed and was fairly steady until May 2020. To complement workouts like this, products that are aimed for men over 50 can be used.
In May, my wife refused to let me walk for more than an hour a day. It took me a few months to convince her and level up. I ended 2020 averaging a little over 10K steps for the year.
I’m becoming more regular. I walked 10K/day 15% more in 2020 than in 2018.
2018: I walked 10K steps almost half the time. 2019: it grew to a bit more, to 56%. 2020: I walked 10K steps a day almost two-thirds of the time.
But in May 2020, I went for 5 days without walking even 3K steps.
In 2018, I started being more and more regular until my leg started aching. 2019 was fairly consistent. 2020 is when I applied brakes again — for very different reasons.
I’ve never gone for 5 days without walking even 3K/day before, since 2018. At most, it was 3 days at a stretch.
But when my wife refused to let me walk for more than an hour a day in May 2020, I went on strike! 😉
I walk ~77 min daily. This has increased over the years.
In 2020, this has gone up slightly to 84 min — but it’s still under an hour-and-half. I spend most of this time on calls or listening to audio books / podcasts. Instead of spending it with my family.
Sometimes, I lose myself in calls and walk for almost 3 hrs and 20K steps.
Naveen is usually to blame. But this happens rarely. I walked 20K steps just 6 times over the last 3 years.
Though the longest walk here indicates over 3 hrs, I’ve never walked 3 hrs in a day.
On 21 Nov, my daughter borrowed my phone and went for her walk. So my phone shows our combined walks, not mine. Many of the other long walks are spread out during the day when I commute by walking in Singapore.
Date
hrs
km
#
Why?
21-Nov-20
3.46
15.5
1
My daughter took my phone. These are her + my walking stats.
15-Nov-19
2.98
11.5
2
Walked to meetings in Singapore.
17-Sep-19
2.96
10.7
3
Walked to meetings in Singapore.
11-Jul-20
2.89
13.9
4
Was talking to Pratap & Ganes.
15-Oct-18
2.83
9.5
5
Walked to meetings in Singapore.
03-Sep-20
2.82
13.0
6
Was talking to Naveen & my coach.
I want to walk faster. I walk at ~4.4 km/hr. My target is 5 km/hr.
Walking at over 5 km/hr speeds the heart up and improves metabolism. (Or so I’ve heard.)
I was steadily going towards 5 km/hr in my early days of walking. I slowed down starting Aug 2018, since my legs were aching. Then I picked up speed in end-2018.
I slowed down again in Nov 2019 — and I don’t remember why.
In Jun 2020, I started walking much faster — mainly to complete 10K steps within the hour my wife gave me. That seems to have had a lasting impact. I walked faster overall in 2020.
I’ve managed fast walking 66 times in 2020, a bit more than before.
In Jun 2020, I walked at over 5 km / hr on 20 / 30 days — a very consistent high speed. I’ve never gotten close to this any other month. (Clearly, there are adverse effects of being able to convince my wife.)
The fastest I walked was in 2018, at 6.8 km/hr. It might have led to my leg aches.
My top 5 walking speeds were in 2018. In 2020, I’ve managed to walk faster than 6 km / hr just once.
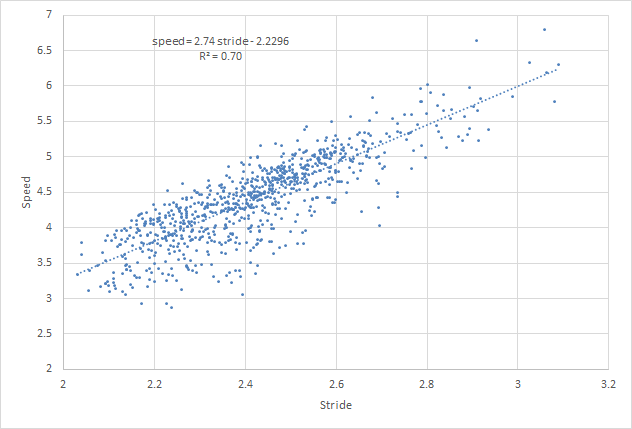
By increasing my stride by 2 inches, I can cover 10,000 steps in 8 min less time.
For every inch I lengthen my stride, I walk ~0.2km/hr faster.
I’ve walked with a stride as long as 32″, which is 3″ more than my 2020 average stride. By walking with a 2″ longer stride, I can be 9.2% faster.
So in 2021, I plan to get healthier (and scolded less) with a 2″ longer stride.
A longer stride means a faster walk. That’s a good cardio exercise. A faster walk also means that it takes less time. So I’ll get beaten up less. All it takes is stretching my legs 2″ more. Might hurt a bit. I’ll report on this when I know better.
Now
New
Change
Benefit
Longer stride
29″
31″
2″
Builds character?
Faster walk (kmph)
4.5
5.0
0.5
Better cardio exercise
Time to 10K steps (min)
84
77
-8
Less scolding from wife
PostScript: This analysis was done in Excel. Download see the sheet below.