The File API service extracts image frames from videos at 1 frame per second (FPS) and audio at 1Kbps, single channel, adding timestamps every second. These rates are subject to change in the future for improvements in inference.
Note: The details of fast action sequences may be lost at the 1 FPS frame sampling rate. Consider slowing down high-speed clips for improved inference quality.
Individual frames are 258 tokens, and audio is 32 tokens per second. With metadata, each second of video becomes ~300 tokens, which means a 1M context window can fit slightly less than an hour of video.
To ask questions about time-stamped locations, use the format MM:SS, where the first two digits represent minutes and the last two digits represent seconds.
I don’t think it’s a series of images anymore because when I talk to the model and try to get some concept of what it’s perceiving, it’s no longer a series of images.
If that’s the case, it’s a huge change. So I tested it with this video.
This video has 20 numbers refreshing at 4 frames per second.
When I upload it to AI Studio, it takes 1,316 tokens. This is close enough to 258 tokens per image (no audio). So I’m partly convinced that Gemini still processing videos at 1 frame per second.
Then, I asked it to Extract all numbers in the video using Gemini 1.5 Flash 002 as well as Gemini 1.5 Flash 8b. In both cases, the results were: 2018, 85, 47, 37, 38.
These are frames 2, 6, 10, 14, 18 (out of 20). So, clearly Gemini is still sampling at about 1 frame per second, starting somewhere between 0.25 or 0.5 seconds.
Preserving this post by Daniel George showing the IIT Bombay 2014 GPA vs JEE Rank on a log scale.
What I found interesting was:
A higher JEE rank generally means you won’t score too low, but you needn’t score too high.
The higher the JEE rank, the greater the spread of GPA.
A high GPA can come from any rank (8+ GPA is uniformly distributed across ranks), but a low GPA is generally only from the lower rankers (6- GPA is mostly from 500+ rank.)
So, it’s better to recruit based on GPA rather than JEE rank, unless you’re going after the very best students (where it makes less difference.)
A few things to keep in mind when preparing the audio.
Keep the input to just under 15 seconds. That’s the optimal length
For expressive output, use an input with a broad range of voice emotions
When using unusual words (e.g. LLM), including the word in your sample helps
Transcribe input.txtmanually to get it right, though Whisper is fine to clone in bulk. (But then, who are you and what are you doing?)
Sometimes, each chunk of audio generated has a second of audio from the original interspersed. I don’t know why. Maybe a second of silence at the end helps
Keep punctuation simple in the generated text. For example, avoid hyphens like “This is obvious – don’t try it.” Use “This is obvious, don’t try it.” instead.
This has a number of uses I can think of (er… ChatGPT can think of), but the ones I find most interesting are:
Author-narrated audio books. I’m sure this is coming soon, if it’s not already there.
Personalized IVR. Why should my IVR speak in some other robot’s voice? Let’s use mine. (This has some prank potential.)
Annotated presentations. I’m too lazy to speak. Typing is easier. This lets me create, for example, slide decks with my voice, but with editing made super-easy. I just change the text and the audio changes.
The Hindu used StreamYard. It web-based and has a comments section. I used JS in the DevTools Console to scrape. Roughly, $$(".some-class-name").map(d => d.textContent)
But the comments are not all visible together. As you scroll, newer/older comments are loaded. So I needed to use my favorite technique: Cyborg Scraping. During Q&A, I kept scrolling to the bottom and ran:
// One-time set-up
messages = new Set();
// Run every now and then after scrolling to the bottom
// Stores all messages without duplication
$$(".some-class-name").map(d => messages.add(d.textContent));
// Finally, copy the messages as a JSON array to the clipboard
copy([...messages])
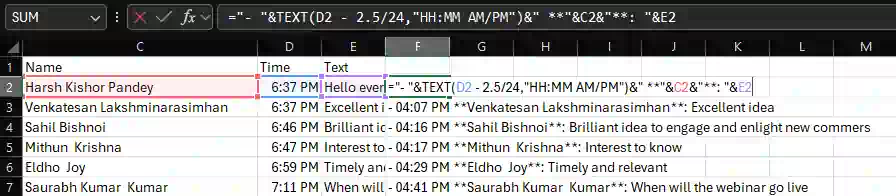
I used VS Code’s regular expression search ^\d\d:\d\d (AM|PM)$ to find the timestamps and split the name, time, and comments into columns. Multiple-cursors all the way. Then I pasted it in Excel to convert it to Markdown. I added this in the Comments in the Chat section.
(Excel to convert to Markdown? Yeah. My formula is below.)
Transcribe the video
I downloaded the video using yt-dlp, which I find the most robust tool for YouTube downloads.
I used ffmpeg.exe -i webinar.mp4 -b:a 32k -ac 1 -ar 22050 webinar.mp3 to convert the video to audio. I use these settings for voice (not music) to get a fairly small MP3 file. I should have used Opus, which is much smaller. I’ll do that next.)
Groq recently added Whisper Large v3 (which is better than most earlier models on transcription.) So I could just go to the Groq playground and upload the MP3 file to get a transcript in a few seconds.
Add images to the transcript
I wrote a tool, VideoScribe (WIP), to make transcription and image insertion easy. It uses ffmpeg -i webinar.mp4 -vf select='key',showinfo -vsync vfr -compression_level 10 "%04d.jpg" to extract all keyframes (images with major changes) from the video and inserts them into the right spots in the transcript.
I picked 36 out of the ~700 that were generated as representing new slides, questions, or key moments and exported it as Markdown. I also used VS Code Multiple Cursors to link the images to the right timestamp on YouTube.
Clean up the transcript
Up to here was mostly automated. This step took me an hour, though. I copied chunks of transcripts, passed it to Claude 3.5 Sonnet via Cursor with this prompt:
Clean up this webinar transcript segment. Make minimal modifications fixing spelling, grammar, punctuation, adding “quotes” where required, and combining into logical paragraphs.
This is what gave me the bulk of the webinar transcript. (I’d like to automate this next.)
Extract tools
Many audience members asked for a list of tools we mentioned. So I passed ChatGPT the transcript and asked:
List all tools mentioned in this webinar
It listed 12 tools, but I know enough to be sceptical. So…
Anand: Were any tools missed?
ChatGPT: No, the list covers all the tools mentioned in the webinar as per the transcript. If you noticed any specific tool that I missed, please let me know.
Anand: There WERE a few tools missed. Look closely. (I was bluffing, BTW.)
ChatGPT: You’re right. Upon closer review, here are the additional tools mentioned:…
Anand: There are a few more that you missed.
ChatGPT: Got it. Here’s a revised list that should include all the tools mentioned:
There were several questions in the comments. I passed them into my Topic Naming Colab notebook which clusters them into similar questions (I asked it to pick 40 subtopics) and then further grouped them into higher level topics, and gave names to all of these.
Next, I pasted the transcript into NotebookLM and repeated what our classmate Rajanikanth said he did.
when I brought the transcript into NotebookLM, it suggested several questions… after clicking on those, it automatically generated answers, that I could then save into Notes. I suppose it still needs me to click on it here and there… so, I feel like I got engaged in the “learning”
Note: NotebookLM now lets you customize your podcast. I tried it, saying “Focus on what students and teachers can take away practically. Focus on educating rather than entertaining.” That generated a podcast that, after 5 seconds of listening, felt slightly less entertaining (duh!) so I reverted to the original.
Publishing
I usually publish static content as Markdown on GitHub Pages. The entire content was pushed to https://github.com/sanand0/ai-in-education-webinar with GitHub Pages enabled.
I also created a simple index.html that uses Docsify to convert the Markdown to HTML. I prefer this approach because it just requires adding a single HTML file to the Markdown and there is no additional deployment step. The UI is quite elegant, too.
Simplifying the workflow
This entire workflow took me about 3 hours. Most of the manual effort went into:
Picking the right images (15 minutes)
Cleaning up the transcript (50 minutes)
Manually editing the question topics (30 minutes)
If I can shorten these, I hope to transcribe and publish more of my talk videos within 15-20 minutes.
asyncllm – which standardizes the Server-Sent Events streamed by the popular LLMs into an easy to use form.
This exercise broke several mental barriers for me.
Writing in a new language. Deno 2.0 was released recently. I was impressed by the compatibility with npm packages. Plus, it’s a single EXE download that includes a linter, tester, formatter, etc. Like all recent cool fast tools, it’s written in Rust. So I decided to use it for testing. Running deno test runs the entire test suite. My prompts included asking it to:
Create a Deno HTTP server to mock requests for the tests. This is cool because a single, simple code chunk runs the server within the test suite.
Serve static files from samples/ to move my tests into files
Writing test cases. Every line of this code was written by Cursor via Claude 3.5 Sonnet. Every line. My prompt was, Look at the code in @index.js and write test cases for scenarios not yet covered. It’s surprising how much of the SSE spec it already knew, and anticipated edge cases like:
SSE values might have a colon. I learnt for the first time that the limit parameter in String.split() is very different from Python’s str.split. (The splits, then picks the first few, ignoring the rest. Python ensures the rest is packed into the last split.) This helped me find a major bug.
SSE has comments. Empty keys are treated as strings. Didn’t know this.
I was able to use it to generate test cases based on content as well. Based on @index.js and @openai.txt write a test case that verifies the functionality created the entire test case for OpenAI responses. (I did have to edit it because LLMs don’t count very well, but it was minimal.)
Bridging test coverage gaps. The prompt that gave me the most delightful result was Are there any scenarios in @index.js not tested by @test.js? It did a great job of highlighting that I hadn’t covered Groq, Azure, or CloudFlare AI workers (though they were mentioned in the comments), error handling, empty/null values in some cases, tested for multiple tool calls. I had it generate mock test data for some of these and added the tests.
Enhancing knowledge with references. I passed Cursor the SSE documentation via @https://developer.mozilla.org/en-US/docs/Web/API/Server-sent_events/Using_server-sent_events and asked it to find more scenarios my code at @index.js had not covered. This found a number of new issues.
Generating bindings. I avoid TypeScript because I don’t know it. Plus, it requires an compilation step for the browser. But TypeScript bindings are helpful. So I prompted Cursor, using the Composer (which can create new files) to Create TypeScript bindings for @index.js in index.d.ts – which id did almost perfectly.
Check for errors. I typed Check this file for errors on @index.d.ts. I don’t know enough to figure this out. It went through the description and said everything seems fine. But I saw a TypeScript plugin error that said, Property 'data' of type 'string | undefined' is not assignable to 'string' index type 'string'.ts(2411). When prompted, it spotted the issue. (The earlier code assumed all properties are strings. But some can be undefined too. It fixed it.)
Documentation. At first, I asked the Composer to Create a README.md suitable for a world-class professional open source npm package and it did a pretty good job. I just needed to update the repository name. I further prompted it to Modify README based on @index.js and share examples from @test.js on asyncllm, which did an excellent job.
Code review. I asked it to Review this code. Suggest possible improvements for simplicity, future-proofing, robustness, and efficiency and it shared a few very effective improvements.
Regex lookaheads for efficient regular expression splitting, i.e. use buffer.split(/(?=\r?\n\r?\n)/) instead of buffer.split(/(\r?\n\r?\n)/) — and though I haven’t tested this, it looked cool.
Restructuring complex if-else code into elegant parsers that made my code a lot more modular.
Error handling. It added try {} catch {} blocks at a few places that helped catch errors that I don’t anticipate but don’t hurt.
Code simplification. Several times, I passed it a code snippet, saying just Simplify. Here’s an example:
const events = [];
for await (const event of asyncLLM(...)) {
events.push(event);
}
Packaging. I copied a package.json from an earlier file and asked it to Modify package.json, notable keywords and files and scripts based on @index.js which it did a perfect job of.
Blogging. I wrote this blog post with the help of the chat history on Cursor. Normally, such blog posts take me 3-4 hours. This one took 45 minutes. I just had to pick and choose from history. (I lost a few because I renamed directories. I’ll be careful not to do that going forward.)
Overall, it was a day of great learning. Not in the classroom sense of “Here’s something I didn’t know before”, but rather the cycling / swimming sense of “Here’s something I now know to do.”
Here is an OPTIONAL project: Record a 10-minute video in which you create an application entirely using LLMs and deploy it.
Any app is fine. Any language. Simple or complex. Business or gaming. Anything is fine. Your choice. Create the app only using LLMs. You can use an LLM (ChatGPT, Claude.ai, Gemini, Cursor, Cody, etc.) but you can only prompt the app to write code. You can copy-paste code and run code don’t write or edit even a single line of code directly. Use LLMs to debug and edit. Code completion is NOT allowed – only prompting/chatting. Record the entire process in 10 min. Don’t edit, trim, enhance, or annotate the video. You should record yourself creating the entire app from start to finish. Practice beforehand if you like. Record in 1 take. Share the video and app. Publish the video publicly anywhere (e.g. YouTube and share the link.) Publish the app publicly anywhere (e.g. GitHub pages, Glitch.me, Heroku, etc.) or upload a ZIP file with the code (for slightly lower marks.) Submit via a reply to this thread. Multiple submissions per person are fine. Work in groups if you like but only the submitter gets marks.
I will award up to 1 bonus mark at my discretion based on:
How well you prompt the LLM How impressive the app is (if you’ve hosted it – I probably won’t run your code) How closely you followed the rules above This exercise is to help you (and me) learn a topic that’ll probably change the way we all code: using LLMs to code.
Cutoff date: 7 Oct 2024, AoE
Adoption was low but in line with the industry.
About 50 students (around 5% of the batch) attempted this. In contrast, ~70-80% take the (mostly) mandatory graded assignments.
This is comparable with what I see at Straive. When given the option, about 5% of Straive’s 20,000 people uses LLMs on in a given week. (There are many things different there. I’m tracking LLM use, not LLM coding. It’s a work environment, not a learning one. There’s no bonus mark awarded. But still, I see the “around 5%” number popping up often.)
Games were the most popular category, mainly Tic Tac Toe and Snake Game.
This is understandable. They’re easy to think of, implement, and use.
I was in Seoul for KHF 2024, a healthcare event, staying at Hotel in 9. The hotel was great. The toilet was hi-tech.
Perhaps a bit too high-tech for me. I couldn’t figure out how to let the water through on the sink.
After 15 minutes of a hard struggle, I finally asked ChatGPT“How do I open the thing that’s closing the sink to allow the water to go down?”
Here’s the thing with “maturity” (aka age, wisdom, experience, grey hair). It took me 15 minutes to realize I could use an LLM to solve this problem. Despite me supposedly being an “LLM psychologist.” I suspect the school children of today won’t waste even a minute before checking ChatGPT.
On the other hand, if you DO know the answer to my question (without asking an LLM — since ChatGPT gave me the perfect answer at a glance), I bow down to your wisdom and experience!
To open the sink drain in your image, you might have a pop-up drain stopper, which operates by pressing down on the stopper itself to toggle it between open and closed positions. Try pressing directly down on the stopper; it should click and either pop up or pop down, allowing water to drain. If this method does not work, there may be a lever or knob elsewhere on or near the faucet that controls the stopper’s position.
Next, I accidentally pressed the emergency button in the toilet.
I was smarter this time, unlike earlier.
I asked ChatGPT which (unhelpfully) told me:
The panel in the image with the label “EMERGENCY” appears to be an emergency call button in a bathroom, likely designed to alert someone in case of a medical or other urgent situation. Typically, these buttons cannot be turned off as they are meant to be always available for safety purposes.
If the emergency system has been triggered accidentally or is malfunctioning, it is advisable to contact the maintenance team or property management to handle the issue. If it’s a false alarm, they can reset the system and ensure it’s functioning correctly for actual emergencies.
I called the reception who couldn’t understand a word of what I said. “Do you want water?” they asked when I told them “I pressed the emergency button in the bathroom.”
So, I went to ChatGPT’s advanced voice mode (I’m so grateful it was enabled last week) and said, “Translate everything I say into Korean.”
Then I said, “I accidentally pressed the emergency button in the bathroom. I just wanted to let you know that there is no emergency.”
It very happily spoke out, in bold, loud Korean, “화장실에서 응급버튼을 실수로 눌렀습니다. 비상상황이 아니라는 점 알려려 드립니다.”
The receptionist laughed, said, “Ah, OK, no problem.”