The Almanack of Naval Ravikant. It’s the best non-fiction I’ve read in 5 years. It focuses Wealth and Happiness. It’s short. I finished it in a day. But it’s deep. I can spend a decade practicing just a single sentence. It’s available at navalmanack.com as a free e-book and audio book.
Rhythm of War. The 4th book of the Stormlight Archives is an action-packed fantasy. A great gift for teenagers. In an extra-ordinary magic system, Brandon Sanderson builds up to the greatest climax I’ve read. What an ending!
Death Note #1-#12. Light Yagami gets hold of a “death note”. If he writes a name on it, they die. “L” is out to catch him. In a cat-and-mouse psychological thriller, Light and L work next to each other, share their plans, and still try to outwit the other. It’s like chess. The pieces are visible. But it’s the strategy that counts. A brilliant comic series.
Life-changing
Atomic Habits. A systematic, well-researched approach to creating (and stopping) habits that last. It’s the best “Habits” book in the market right now..
Being Mortal. A thoughtful, practical guide on dealing with old age. Must read for those with aging parents. It helps that Atul Gawande is a great storyteller and draws from his personal experiences.
Originals. Teaches you how to be more creative and take risks safely. If Creativity Inc inspired you, this book is a way to build Pixar’s magic into your teams. An easy-to-read piece by Adam Grant, backed by solid research.
Combatting Cult Mind Control. The gold-standard in knowing when someone’s in a cult, and how to escape the cult. Opened up a whole new world for me.
Rich Dad Poor Dad. Teaches you to make money work for you rather than you working for money. I was shocked when I realized that the middle class buys liabilities (a house to live in) while the rich buy assets (a house to rent out).
Think Again. Teaches you how to stop fooling yourself and avoid blindspots by checking your assumptions, enjoy learning from mistakes, and open up people’s minds — especially your own. Yet another easy-to-read piece by Adam Grant, backed by solid research.
Influence. A research-backed guide on the science of influencing people subconsciously. Reciprocity, consistency, social proof, authority, scarcity — these are signals we react to unknowingly.
Dawnshard. Book #3.5 of the Stormlight Archives. A handicapped shipowner and her winged reptile pet travel to a mysterious island that no one returns from. With a typical Brandon Sanderson climax that moves this from “interesting” to “life changing”.
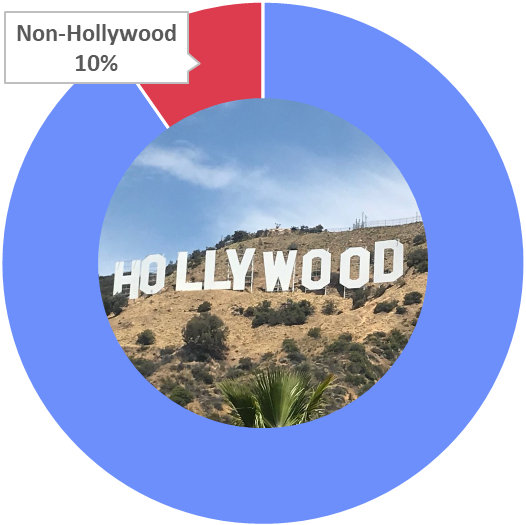
I am a 18-year old biracial Malaysian kid who wants to be an actor in Hollywood. I’m taking a diploma for performing arts in a college called Sunway University in 8 days and I’m considering pulling out of it because why do something that I like when my dreams might never be fulfilled and the price for taking this diploma is seriously expensive. I am starting to doubt my chances of making it to Hollywood and I suffer from extreme anxiety. Is it possible for someone like me to enter Hollywood? What are my chances?
Breaking into Hollywood is hard. As a foreigner, it would be even harder. So I asked myself:
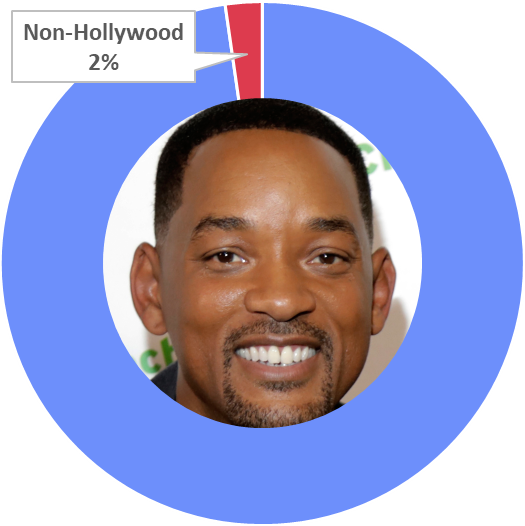
His every co-star is a Hollywood actor, except the Spanish actor Jordi Mollà in Bad Boys II, and the Dutch actor Marwan Kenzari in Aladdin. Will Smith acts with just 2% of foreign co-stars.
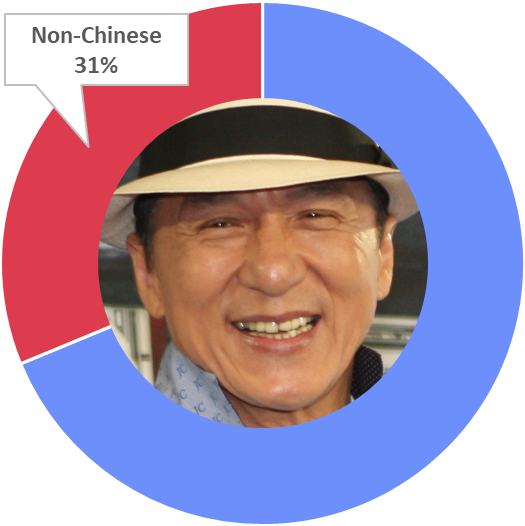
On the other hand, Jackie Chan is more cosmopolitan. He acts with:
Of his 224 co-stars, 70 are non-Chinese. Jackie Chan acts with over 30% foreign co-stars.
Are Chinese films be more foreigner-friendly? Should our Malaysian friend try there instead?
Is Hollywood less open to foreigners than other countries?
I took all movie actors across the world and broke them into groups using a community structure. Actors within the group act mostly within themselves, and less with other groups.
The largest group is Hollywood, with ~80,000 actors (mostly American). They act with each other 90% of the time and act with other groups only 10% of the time.
In comparison, the Chinese group has ~20,000 actors. They act with each other 98% of the time. When they do act outside the group, it’s mostly with Hollywood (0.5%), Japanese (0.3%), South Korean (0.3%), and Indonesian (0.1%)
Clearly, Jackie Chan is more the exception than the norm.
But among the large groups, there are 2 groups that are even more insular than Chinese actors.
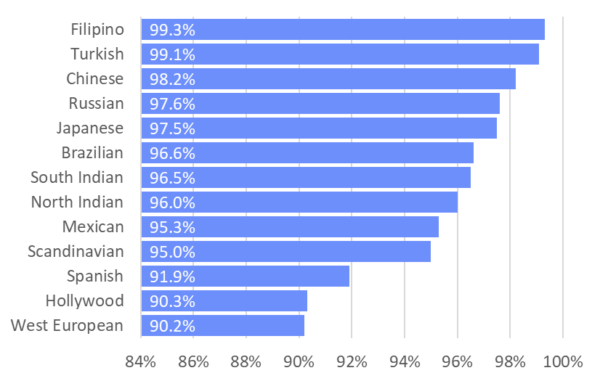
The ~8,200 Turkish actors act only with each other 99.1% of the time, occasionally venturing to act with Iranian actors (0.2%).
Even more insular are the ~7,000 Filipino actors who act with each other 99.3% of the time. They occasionally venture out to act in Hollywood 0.2% of the time.
There are no other sizeable groups of actors that’re as insulated.
Hollywood is actually among the most cosmopolitan groups, along with the West European films. So, to our budding Malaysian actor, I’d say:
It’s hard to get an acting break. As a foreigner, it’s 10 times harder in Hollywood. But you’re better off in Hollwood or Western Europe than in any other country, where it would be 50 to 100 times as hard!
What do you pick for someone you don’t know well enough?
I generally pick books. I know books well enough to match them to people’s personalities. Even if they’re not a book reader. (The risk is that they might have already read the book.) As for the kids, toys like the tiny tower diy playhouses for sale would bring them so much joy.
The other safe item is food. Chocolates, dry fruits, etc. Everyone likes them. (Even if they’re dieting, dry fruits and dark chocolates are fine.)
Beyond that, it’s a hard problem.
I went through some populargiftchoices. There are a few good ideas there, but very few safe bets. For example:
A Tortoiseshell Face Mask Chain. What’s that?
A stress relief ball or perhaps other stress-relieving products from sites like CBD UK. Hmm… not a bad idea, actually.
A notebook. Except that I stopped writing in 2001.
A USB rechargeable lighter. But who do I know that smokes, whom I want to encourage?
A purse. I’ve never bought one in my life. My wife never likes the ones I point to. So…
A hot water flask. Again, not a bad idea, actually.
… and the lists go on.
But most gifts I receive for my talks are promotional.
Plaques or certificates. Some people put these up in their cabin. I don’t have a cabin.
Branded photo frames. I don’t have photos either.
Company-branded USB car USB charger socket. I don’t drive much.
Their book or brochure. I’ve either already read it or never will.
What I’m going to be talking about is how you can get insights by joining two maps but before we go there, just some basic bookkeeping things.
In case you’re tweeting, these are the hashtags, you probably want to be using the #PyconIndia, my hashtag my IDs, #SANAND0, you don’t need to worry about the slides, they are online. I’ve already posted on Twitter, the link to the slide deck, the slide deck that you’re using but if you desperately do want to take notes, then one small suggestion. Research has shown that taking notes on pen and paper is much better than taking notes on laptops if you want to remember stuff or on mobile phones. So this was a discovery for me. In fact, it was my discovery of the year and I’m following it diligently. Do give it a shot if you want to take notes. Let’s dive in.
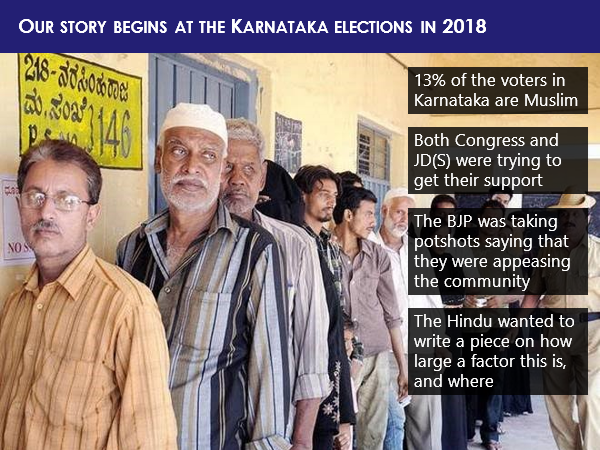
The story begins at the Karnataka elections in 2018. Say about one-eighth of the voters are Muslim, and both the Congress as well as the JD(S), were trying to get their support while on the other hand, BJP was taking potshots saying both of them are just trying to appease the community. The Hindu newspaper wanted to write a piece about how large a factor this is, and where all the Muslim vote is strong. You see, here we have a problem.
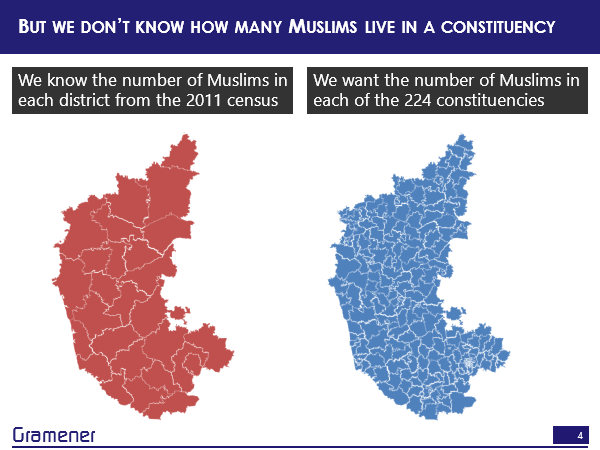
The thing is that the proportion of the population by religion is available only at the district level or the village level, depending on where you get the data from and this is from the census. Unfortunately, elections are not conducted by the district, elections are conducted by constituency and these are two very different maps. So, I have data in one map, which shows me how many Muslims exists in a particular region and I want to see how many Muslims live in a different region on another map and even though they overlap, there really is no direct way of getting the data from one layer on to the other. So, we literally don’t know how many Muslims live in a constituency.
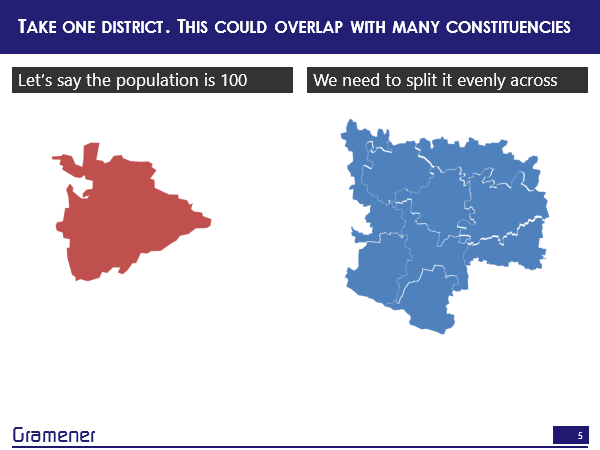
So, how do we solve this problem? Well, the logical way is you could take one district and a constituency or a set of constituencies, and let’s say the district has a population of 100, out of which we know that 13% are Muslims and we want to split it evenly across a bunch of constituencies.
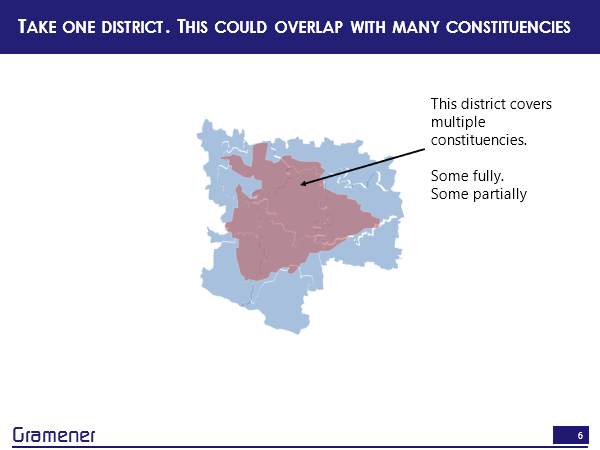
We could just overlay them. So one district could cover multiple constituencies, one constituency could cover multiple districts, and there is a many to many mapping between these there is sometimes full coverage, sometimes partial coverage.
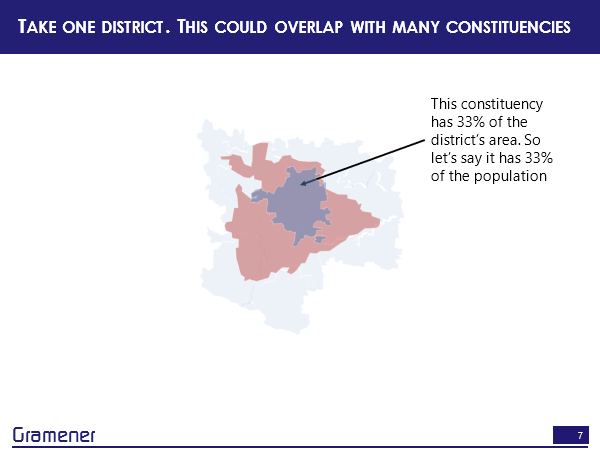
So this district, for instance, covers at least one constituency fully and maybe this takes up about 1/3 of the total area. So I can say approximately 1/3 of the district’s population, which is that red area lives in this constituency.
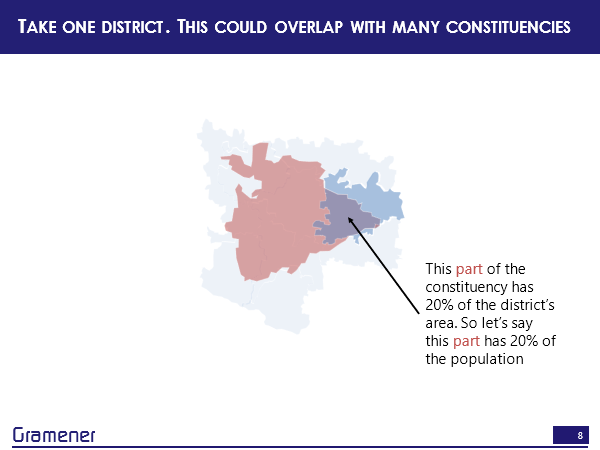
Or let’s take another constituency that overlaps with this district. So, now only a portion of this constituency overlaps with this district. So in this area, which takes up maybe about 1/5, or about 20% of that district population, I can say that population lives here. In other words, we are simply making an assumption that within a district, which is the lowest level of data that you have, or if you have village data that’s far more granular, the population is uniformly distributed. That’s the basic assumption.
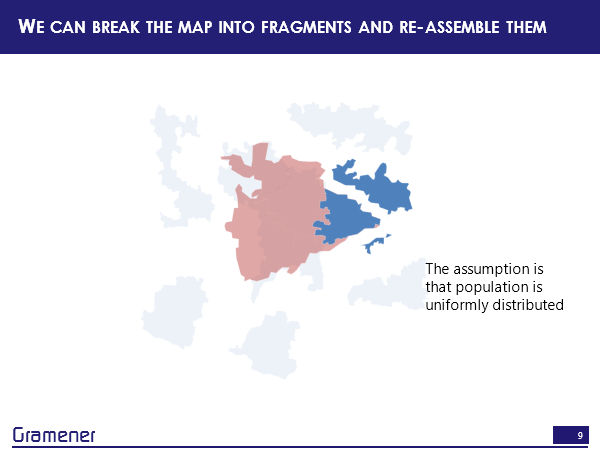
Now, what we can do is fragment each of these districts and constituencies by overlaying them and creating an intersection out of those, and reassembling those and this is a process that I call reshaping the map.
How much of this can we do in Python? There is a library called reshaper that we put together. The reshaper Library is something that’s very work in progress by the way. You can find it github.com/gramener/reshaper. It does exactly what I’m about to show you right now.
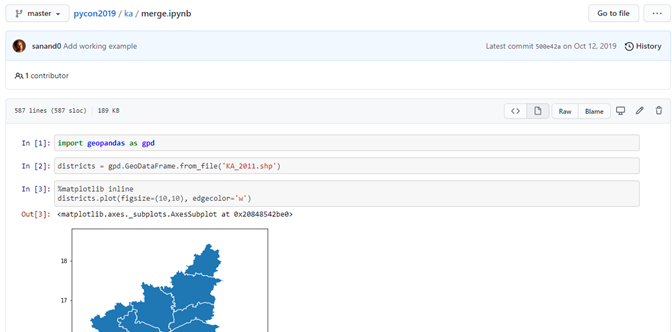
So let’s give it a shot. I’m going to open up the IPython notebook. The library that we are going to be using for this primarily, the core library is Geopandas. For those of you who have been working with data, Pandas is pretty much the de-facto library to use for any kind of data processing. Geopandas is becoming that kind of a standard for any shapefile. So if you have any shapefile and you want to do any kind of geospatial processing, an easy way of doing it is Geopandas and an easy way of installing it is through Conda using Anaconda. Rather than trying to do a pip install by yourself. It’s a little more efficient on most machines. So let’s import Geopandas. Now I have a shapefile that has the Karnataka census data which will eventually appear. I’m going to load it once it appears on the screen. (Just taking a long time. Okay, there we are back again.)
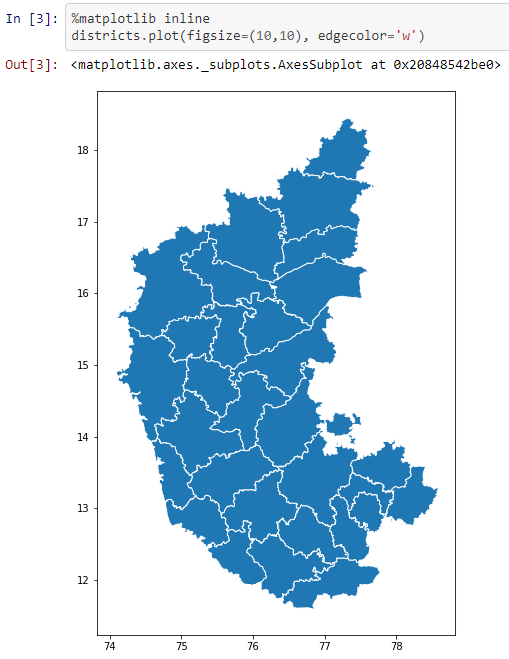
So GPD, which is the abbreviation for Geopandas, has a from_file function that lets you load any shapefile. Now, the other question you’ll have is where am I going to get these shapefiles from? We’ll come to that in a bit. It’s not as difficult as you might think. Let’s say you’ve downloaded the shapefiles. This particularly is the Karnataka census shapefile and what does this look like? Geopandas has a plotting function, which lets you see what the map looks like. So if you look at these districts, this is a pretty large district, this is Bangalore.
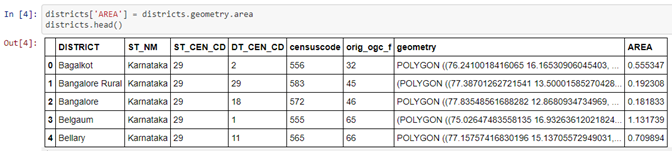
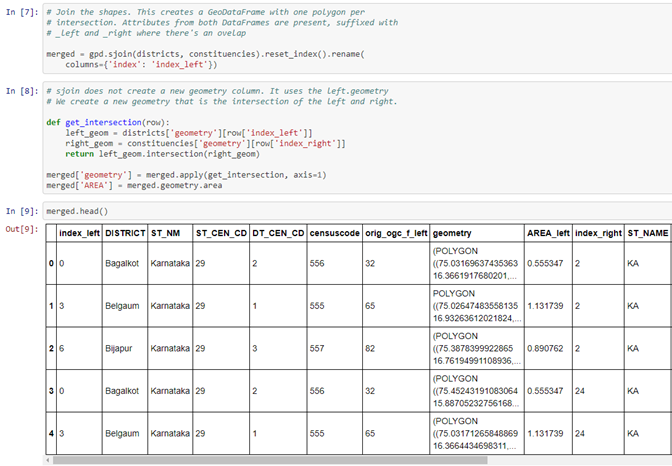
Let’s take the area for these. Geopandas offers an attribute called .geometry, which has an attribute called .area, which gets you the overall area of each of these regions, and if you want to look at what that data frame looks like, each of these regions corresponds to one row. So the Bagalkot district is one row, Bangalore rural district is one row and so on. All of the data in the shapefile also comes in here, you have a column called geometry, which has the additional geometry details, this is a pretty large column, which you probably won’t be going into the details of it. We’ve just now added one column called area, and this has the area of each of these regions and at the very least, you can figure out which are the larger regions, which are the smaller regions.
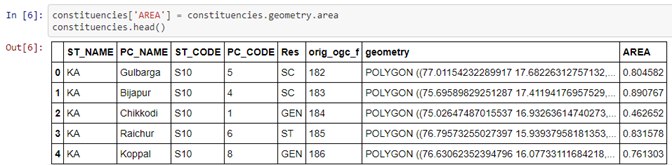
Let’s do the same for the constituencies data set. So here we have the constituencies that are more, these are parliamentary constituencies, by the way, not assembly constituencies. The difference being if you’re electing someone for the parliament, it’s or an MP, then it’s a parliamentary constituency. If you’re electing them for the assembly, which is an MLA, then it’s the assembly constituency. Parliamentary constituencies are bigger. So you’ll notice that out here, there are multiple parliamentary constituencies that sit in the same region that this district sits in, but it’s not a perfect match. Again, let’s take the area and see what this looks like. We have a bunch of these parliamentary constituencies like Gulbarga, Bijapur, etc, and their respective areas.
Now, Geopandas has a function called sjoin, which lets you take two shapefiles and create all the intersections around those shapefiles the fragments that I just showed you out here. So yeah, creating all these fragments is what the sjoin function does. So, if we do that, then what it’s now done is created a new data frame called merged and that has all these shapes. Let’s validate that. So there are 30 districts and 28 constituencies, but when you overlay them, it turns out that there are 147 fragments, each of which represents an intersection of a district and a constituency. Now, given this, it should be possible to just take any metric, like the percentage of Muslim voters or the number of Muslims, the size of the Muslim population, from the district data into the data that you have on the constituencies.
But it turns out that it’s a little trickier than that. So, you have to do a little more calculation and that’s what’s available in the reshaper library, you can take a look at the code, what it does is moves the metrics from one layer to another in a way that is seamless.
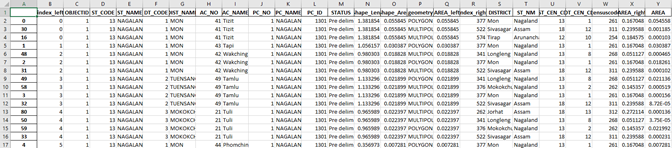
Once we have this, the result is an Excel sheet that kind of looks like this. It has all the attributes from both layers.
So, it says, for instance, that this particular assembly constituency is broken up into three regions, each of which maps to different districts. So some of it overlaps with more and some of it with shift saagar some of it with data and in fact, these are across different states and what is the area of each of these, along with a variety of other metrics that you can calculate and the proportion of area that is overlapping. Once you have this kind of data set, what can we do with it? So let’s revert back to our story.
What actually happened to the Muslim vote?
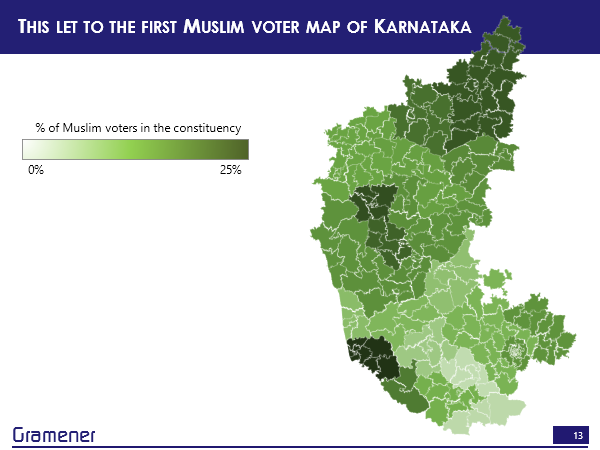
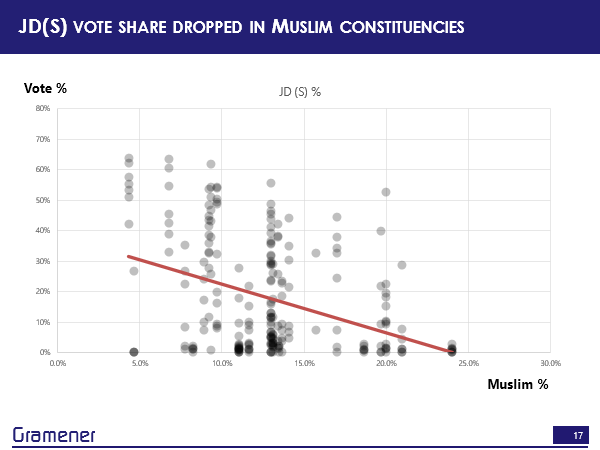
Well, this is the constituency-wise Muslim voter population in Karnataka.
This was used by the Hindu to publish an article around where exactly the bulk of the voters are concentrated. So, there is a chunk here, there’s a chunk here, there’s a chunk here.
Now, what was happening at this particular point was there was a fight for an alliance. The AIMIM, which is a Muslim party whose name is very long, and I can’t even say it fully. But they had won a number of seats in Telangana, and were looking to also participate in the Karnataka elections. They plan to contest in 60 seats. Now, to make sure that they get the Muslim vote, both JD(S) and the Congress were vying for an alliance with the party and in April 2018, AMIM decided that they will not be directly contesting in the elections, but instead would be supporting JD(S). Now, we have the results of the elections by constituency, we know the voter population by constituency. Let us see what happened to JD(S).
Turns out that where there were more Muslim populations, JD(S) actually got lower votes. So you can see the net result of this election and the alliance.
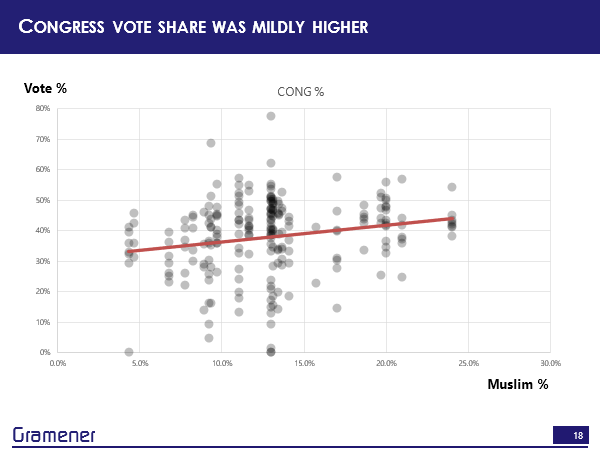
Congress, on the other hand, had a mildly higher vote share and where there was a significantly larger voter population.
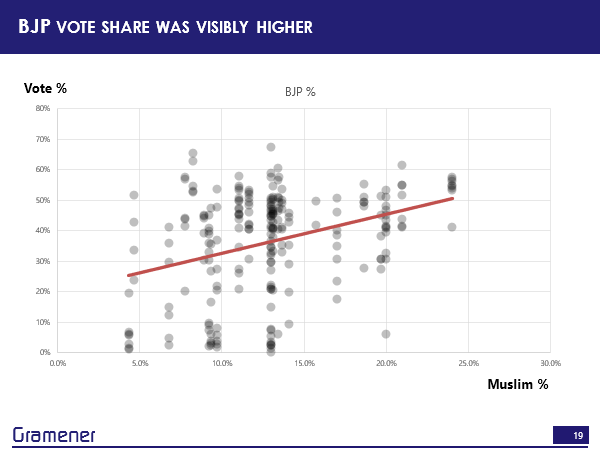
It turns out that BJP was the one that gained the most.
Now while I’m moderately okay, at Python, I’m terrible at electoral analysis. So I have no idea what this means. Okay, I’ll let you figure it out. The elections in Maharashtra and Haryana are also coming up and it turns out that Congress is aligned with AIMIM and, well, let’s just leave it at that.
So, what can we do with this? What kinds of datasets exist and what is the potential of being able to join data sets across two spaces? That’s something that I’m pretty keen on.
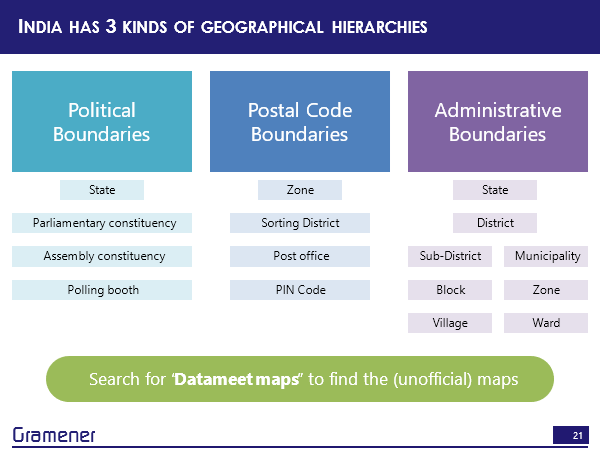
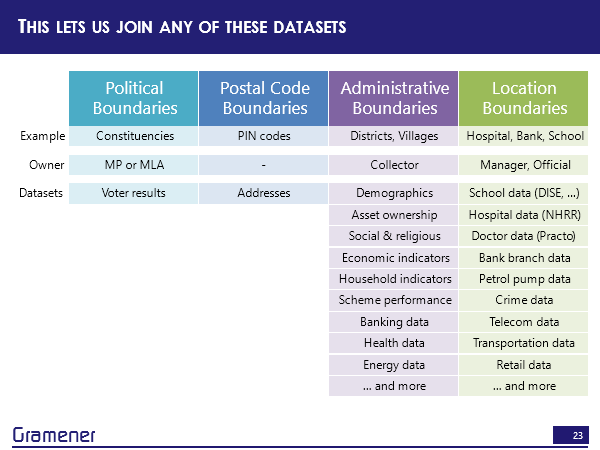
It turns out that in India, there are broadly three kinds of geographic hierarchies. There is a political boundary hierarchy, a postal boundary hierarchy and an administrative boundary hierarchy.
By political boundary, I mean, the state parliamentary constituency, assembly constituency, going all the way down to polling booth. This has all of the results of the elections and one of the important aspects of this is that policies get made to a good extent at this level because the MPs and the MLS are focused on their respective constituencies.
The second is a postal code boundary. There is a zone within which there is a sorting district within which there is a post office and there is a PIN code, there are about 110,000 of these in total.
The third is the administrative boundary hierarchy. So there is a state there is a district, there’s also something called a division, but we’ll leave that aside, then there could be a sub district block or village, if it’s a rural area, or it could be municipality zone and ward if it’s a township.
Now, this apart, there is one other way we can create our own hierarchies. But before that, in case you’re looking for shapefiles, for many of these, the easiest way to get the shapefile for India is to search for “Datameet maps”. Datameet is a group that it’s a discussion forum and there is a lot of active discussion on various kinds of maps, pretty much any kind of map, there’s a decent chance that you’ll find it on Datameet and if it’s not there on Datameet, ask the people, they might be able to post something, and if not, it probably just doesn’t exist.
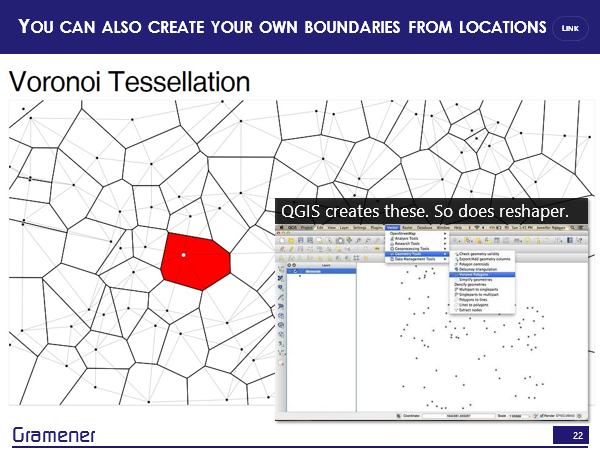
But you can also create your own boundaries. If you have a single location, you can look at the area that is closest to this particular location than any other location. So for example, if this were a network of, let’s say, schools, then what is that vision that is closest to a particular school than any other school.
So if I take this particular point as a school, then this red region represents all of those points which are closer to this school than any other school.
This particular process is called Voronoi tessellation and is something that comes out of box with QGIS, it’s something that you can create with the command line prompt again using the reshape or library, but what that means is that now you can take literally any point and convert that into a region and the potential for that is quite high.
So if I look at the kinds of data sets that you can create with location boundaries, right, so there’s… take all the hospitals, take all the schools, take all the bank branches, take all the petrol pumps take all the locations where crimes have been reported, take any address or take all the telephone towers, take all the locations where there are stores of a particular brand.
All of these are datasets for which you can get an address and an address can be geocoded into a point. If it can be geocoded into a point, you can convert that into a region and for each of these, you naturally have some kind of data for schools, you know how many teachers or how many students that are for telecom towers, you know, which is the organization that runs that tower, potentially the telecom organization will know how many calls are flowing through it, if it’s healthcare data, you know, how many facilities that hospital has, how many patients, how many doctors, all of these are data sets that can be added to that particular cell in your respective region.
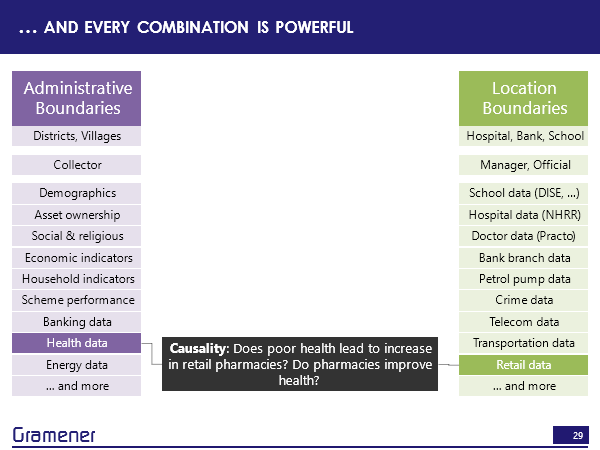
But what this means, therefore, is that if we take any of these data sets that which you can create from location boundaries, or that often already exist by administrative boundaries — and this is a pretty powerful set as well. Census gives us demographic data, asset ownership, who owns laptops, internet connections, TV, cars, fridges, social and religious data, economic indicators, well, income, household indicators, is the house made of a mud roof brick roof, do you have a toilet in the house not have a toilet in the house, practically every government scheme is tracked this way. So how many people have benefited from the National Rural Employment Guarantee act? Banking data is reported this way health data is reported this way.
So effectively, anything that the government runs is reported by administrative boundaries. Anything that the corporate sector runs, by and large, is reported by locations. So between these two, there is enormous potential. But there’s also the fact of how decision making happens. Ultimately, political boundaries are owned, in some sense by an MP or an MLA. And, of course, there is also the associated IAS equivalents, who usually run it by administrative boundaries. So if I wanted somebody on the political side to make decisions, then I could take any of this data and put it on to the constituency boundaries. If I wanted an administrative official to make a decision, then I could take any of this data and put it on to a district. If I wanted a manager or a principal of a school, or the CEO of a hospital to make a decision, I could take all of that data and put it onto their geographic boundary.
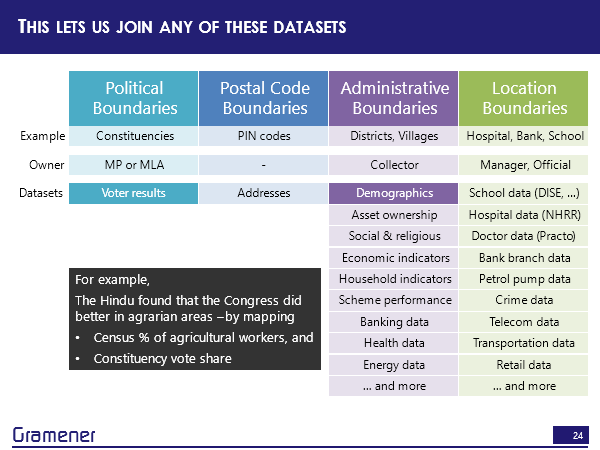
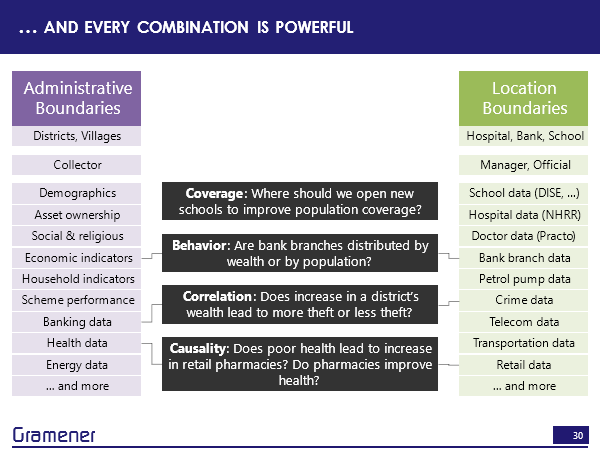
For example, one of the things that the Hindu again did was found that the Congress is doing much better in the agrarian areas and they did that by taking the census data, which had the percentage of farmers and mapping that on to the voter constituency regions.
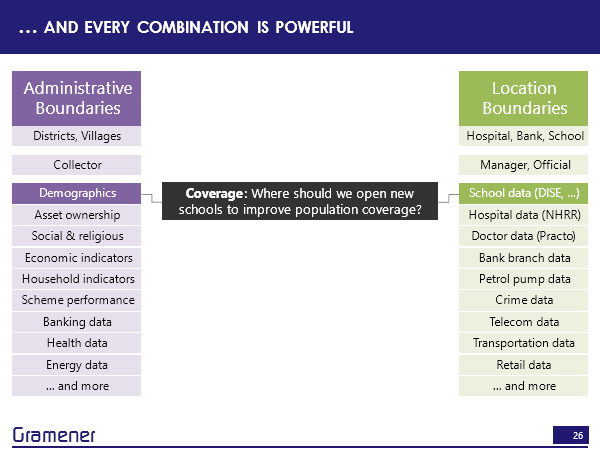
If we took, for example, census demographic data and school data, we can answer a question, where should we open new schools so that students don’t have to travel far or where there is a reasonably equal distribution of students across schools?
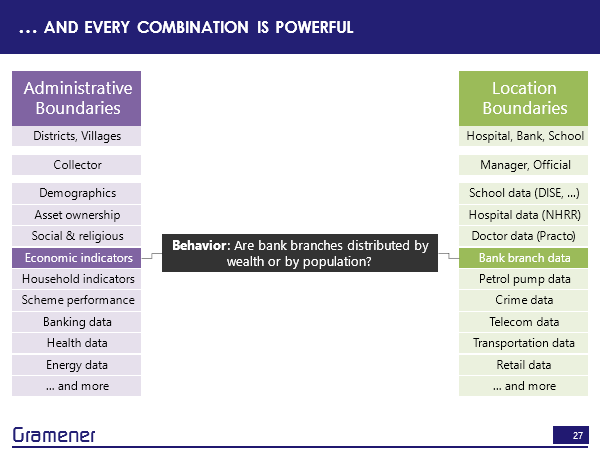
If we took economic indicators how well the country is growing versus bank branch data? Then we can answer questions like are the bank branches distributed? Based on population? That is, does every person roughly have equal access to the bank or based on wealth? Does every rupee have roughly equal access to the bank or if it’s in between? How close is it from one to the other?
We could find out whether increasing the district’s wealth leads to more theft. So that means people get richer. So does that mean that it does that lead to increase in crime? Or does it lead to less theft? Because the people are richer, and they don’t need to steal therefore? And these are data sets that are available and can be joined.
Similarly, with health data, does poor health lead to an increase in the number of pharmacies that are set up in that region because the pharmacies can sell more. Vice versa, if you actually set up more pharmacies? And does that have a positive impact on the people’s health in that particular region?
Now, the reason these questions are trivial to ask, but nearly impossible to solve today is because merging the data across different kinds of layers of maps is non-trivial. But both conceptually and technologically is quite an easy exercise.
What can we do to solve problems like this? Well, me personally, I’d love to see more of these hidden insights come out but there are a few things that you can do, literally right now.
First, if you have an idea, take a look at these data sets, any of the data sets that you know and raise an issue on this particular repository and I’d invite all of you to share this with people. It’ll be great to see what kinds of ideas can be solved using these problems and I’d like to crowd source this to a number of people on the administrative side, on the NGO side, and on the corporate side, to create a repository that says here are things that we can do.
If you want to try solving one of these and discovering your own insight, to build your own portfolio to share some useful knowledge. Then start by finding a map. Like I said, Datameet is a good place where you can find them up. You can find the reshaper library on https://github.com/gramener/reshaper. The links are again, on https://github.com/gramener/pycon2019. This is the one link that you need to remember and if you find something, do share it on Twitter. Please tag me @sanand0, I’d love to share it at least with the media and get some people to understand the power of geospatial joins.
If you want to contribute to the library right now it’s in a terrible state. Or if you want to learn more, I’m planning to organize a series of workshops on geospatial joins, do drop me an email. My email ID is s.anand@gramener.com and I’ll mail you the workshops. If nothing else, if you just enjoyed the talk and you’ve learned something about it, then tweet about it. The tags are #PyconIndia2019, my ID, @sanand0. More than anything else, I’d love to see some insights come out by joining data.
Happy mapping!
Question: So my question is, basically, I’m belonging to northeast part of India. So I’m from Assam. So what happened in terms of the documentation for this geographic data and so those are always kept in a sort of, you know, register. We call registers or something, so how we use that image processing and all like, to enable those things into a more of a like a public space?
Answer: Okay. There are broadly three ways in which you can get this kind of data out. The first is beg, borrow, steal. Somebody in the government may have this data. So for example, if you go to the Survey of India, they sell these shape files. Of course, I’ve been trying to buy one of these shape files for the last six years now and have failed and I’ve tried it through the Prime Minister’s office and I still failed. But it’s actually easier to just walk over to the Survey of India office and give them a USB stick, and they’ll give it. So, depending on how you approach it, it may prove relatively straightforward.
On the other hand, sometimes the maps don’t exist. So for example, most interesting anecdote was the former head of the postal College of Mysore was trying to create a postal map, the region of all of the PIN codes. It turns out that nobody knows what the region is that a PIN code covers. So he created that he uploaded that ISRO’s Bhuvan, and then after about a year and a half realize that people have permission to upload into ISRO but download from Bhuvan. So after one and a half years of putting all the data, the data is locked, it’s not even there. So today, what is the best source of getting PIN code data? It turns out that what people did was took various locations, geocoded them, they said, this location is at that this particular PIN code, this location is at that this particular PIN code, let’s draw a region around it using the concept of Voronoi polygons, and publish it. So the second possibility is to create such maps.
The third possibility that you talked about, which is can we use image processing to detect it? Some features can be detected that way. So, for example, if you want to detect urban regions are constructed regions, that’s possible using satellite photography, if you want to locate water bodies, and whether they are growing or shrinking, so for example, in Chennai, the Chembarambakkam lake actually drying up, that’s something that you can draw a boundary around using image processing and that’s a straightforward method. But the thing is, I don’t think a single method will work for a wide variety of data sets, which is why we have many of these.
But the biggest lesson that I’ve learned is that 90% of the things that we want, somebody else has usually wanted, and has managed to get their inputs. So, I find that the most efficient ways to ask and Datameet is a pretty good place to ask if somebody already has his data.
Question: Anand, thank you very much for your talk. I’ve got a question regarding shape files. I had the requirement of using the map of India a few times and I suddenly realized that our external boundaries in a lot of places are in dispute and the kind of shape files that we get are not matching with what politically we want our file boundaries to be. So is there any official place from where we can get these shape files because the only shape file which are available are those distorted shape files, and I finally had to change the shape files myself to use it. I couldn’t find any official place from where to get the shape file.
Answer: So, the official place is the Survey of India, which claims to sell these maps like I said, for the last five, six years now I’ve been trying to buy these maps it’s actually not possible. But there are people who have succeeded and stock is being recorded, right? Okay. Let’s just say that if you go to Datameet maps, you will get unofficial but correct maps.
Question: So, since you are in the field, shouldn’t we have a system of getting correct official maps? Isn’t there a process being put in place or something?
Answer: I tried talking to a couple of people at the Prime Minister’s office and suggested this. They put me on the phone with the Inspector General of Surveys or some such high ranking official who said yes, absolutely, connected me to some person, who connected me to some person, who connected me to some person, who is exactly the same person I talked to in the first place. So, I don’t know. I’m sure there is a process. I don’t know it well enough.
At first, it shows just 20 people. But as you scroll, it keeps fetching the rest. I’d love to get the full list on a spreadsheet. I’m curious about:
What kind of people follow me?
Which of them has the most followers?
Who are my earliest followers?
But first, I need to scrape this list. Normally, I’d spend a day writing a program. But I tried a different approach yesterday.
Aside: it’s easy to get bored in online meetings. I have a surplus of partially distracted time. So rather than writing code to save me time, I’d rather create simple tasks to keep me occupied. Like scrolling.
So here’s my workflow to scrape the list of followers.
Step 1: Keep scrolling all the way to the bottom until you get all followers.
Step 2: Press F12, open the Developer Tools – Console, and paste this code.
copy($$('.follows-recommendation-card').map(v => {
let name = v.querySelector('.follows-recommendation-card__name')
let headline = v.querySelector('.follows-recommendation-card__headline')
let subtext = v.querySelector('.follows-recommendation-card__subtext')
let link = v.querySelector('.follows-recommendation-card__avatar-link')
let followers = '', match
if (subtext) {
if (match = subtext.innerText.match(/([\d\.K]+) follower/)) {
followers = match[1]
} else if (match = subtext.innerText.match(/([\d\.K]+) other/)) {
followers = match[1]
}
}
followers = followers.match(/K$/) ? parseFloat(followers) * 1000 : parseFloat(followers)
return {
name: name ? name.innerText : '',
headline: headline ? headline.innerText : '',
followers: followers,
link: link ? link.href : ''
}
}))
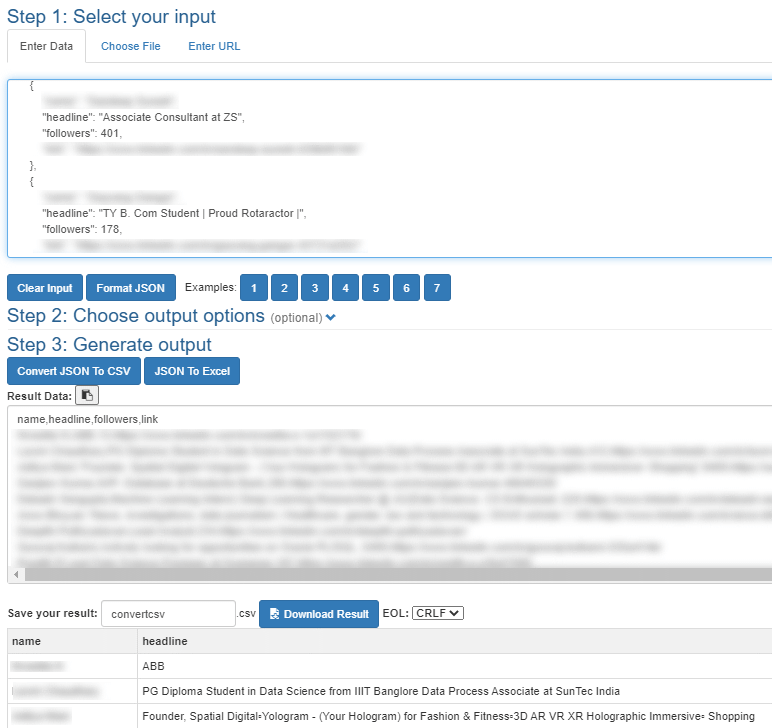
Step 3: The name, headline, followers and link are now in the clipboard as JSON. Visit https://www.convertcsv.com/json-to-csv.htm and paste it in “Select your input” under “Enter Data”.
Step 4: Click on the “Download Result” button. The JSON is converted into a CSV you can load into a spreadsheet.
I call this “Cyborg scraping“. I do half the work (scrolling, copy-pasting, etc.) The code does half the work. It’s manual. It’s a bit slow. But it gets the job done quick and dirty.
I’ll share later what I learned about my followers. For now, I’m looking forward to meetings 😉
PS: A similar script to scrape LinkedIn invitations is below. You can only see 100 invitations per page, though.
I use PowerPoint instead of Adobe Illustrator or Sketch. I’m familiar with it, and it does everything I need.
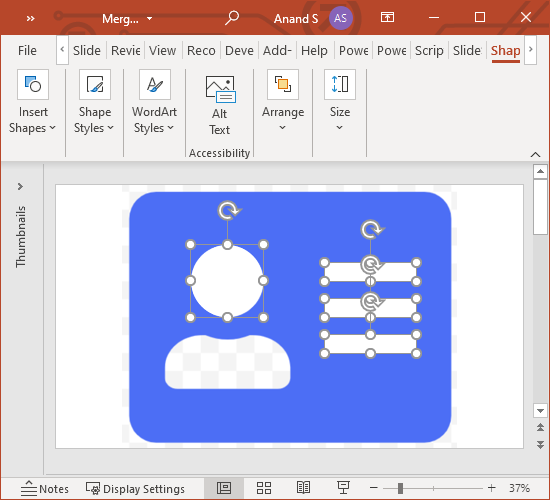
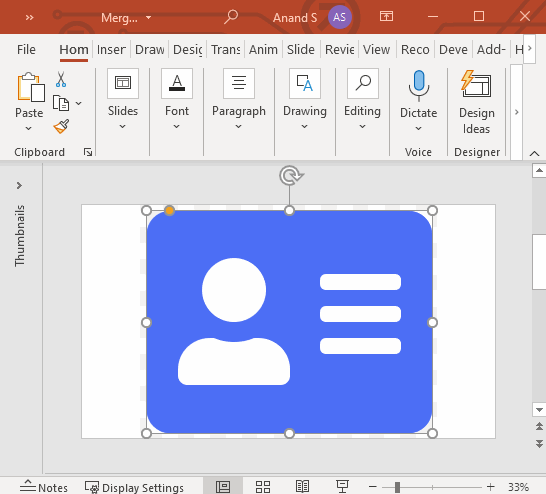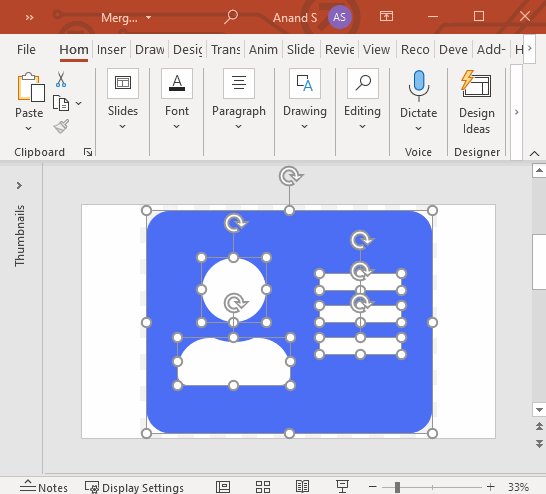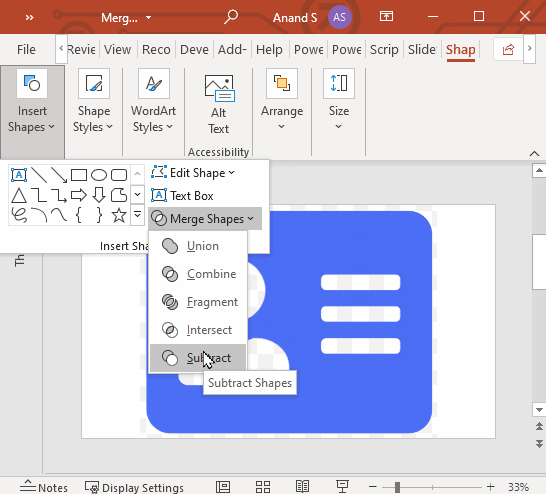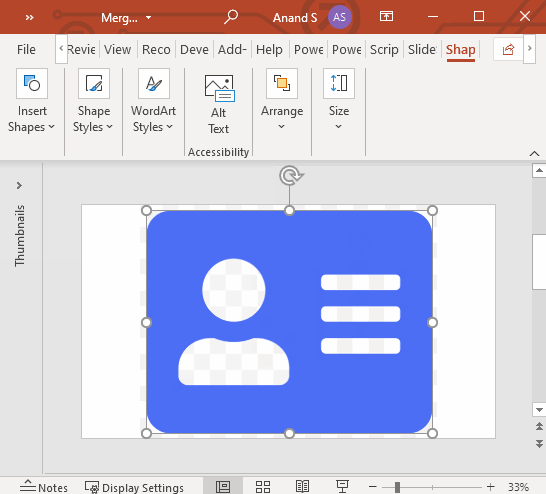
One of the features I’m really excited by in PowerPoint is the ability to manipulate shapes.
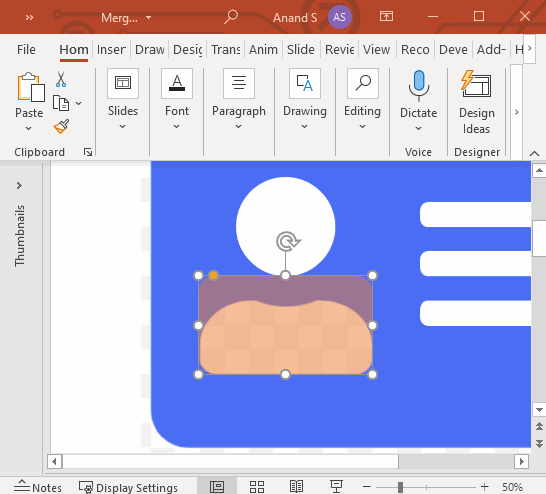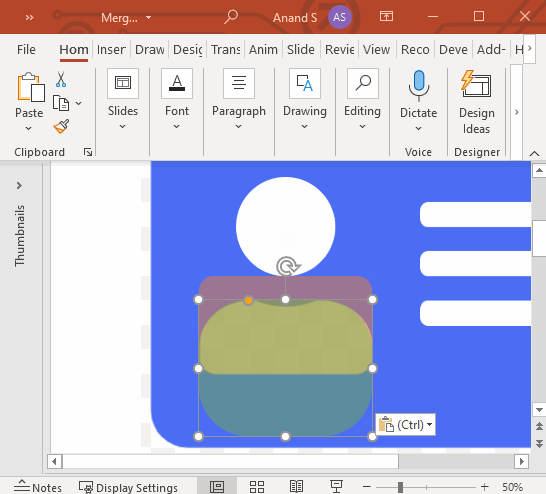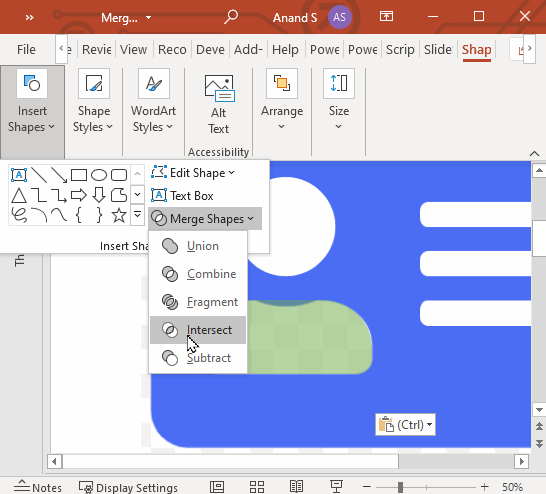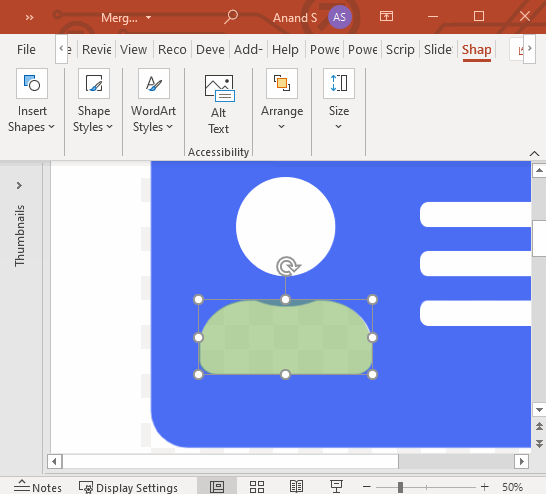
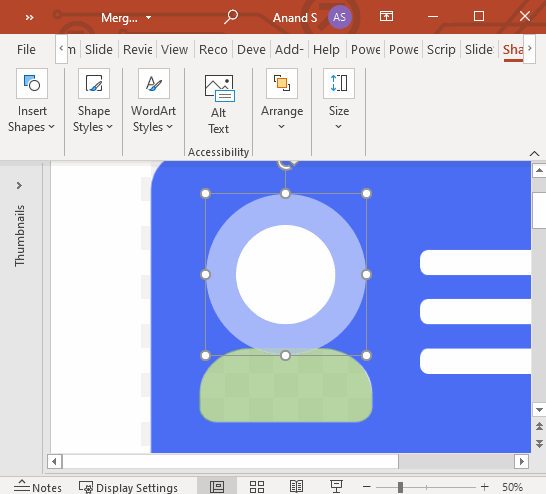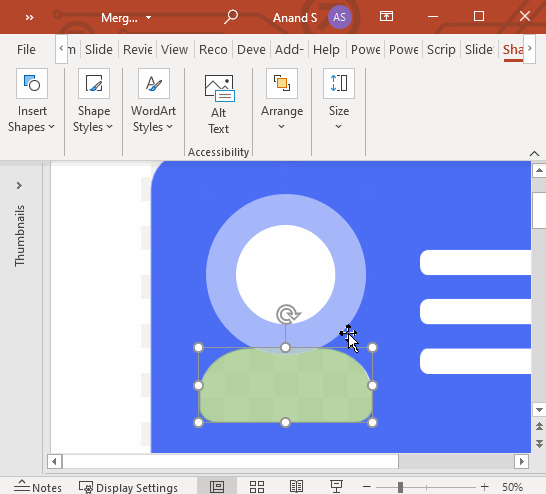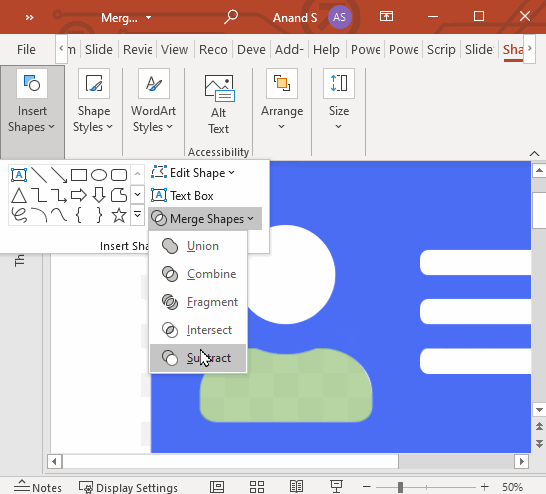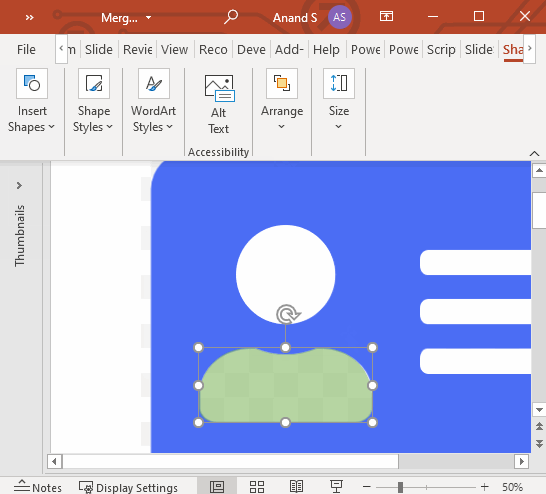
Let’s say you have a rectangle and a circle. You can select both of these shapes and in the Shape Format > Merge Shapes dropdown, you can:
merge them with a union
combine them (like an XOR operation in Boolean algebra)
fragment them, which breaks them up into pieces
intersect them
subtract them
This is so powerful that you can create any kind of shape. Let’s take an icon from Font Awesome at random — say an address card — and create it.
Here’s the video of the process. I’ll explain it step-by-step below.
First, let’s take a screenshot of this and copy it into PowerPoint.
Now let’s draw over this. So we’ll start with a rounded rectangular box with the same color as the address card. We can use the eyedropper to pick the right color. Remove the outline. Then match the edges as closely as you can. (Add a bit of transparency so you can see through it — that helps match edges closely.)
Move this card boundary to a new page.
Now, on top of the original image we copy-pasted from Font Awesome, trace 3 rounded rectangles for the address lines. Trace a circle over the head. Fill them white. Remove the outline. It should look like these.
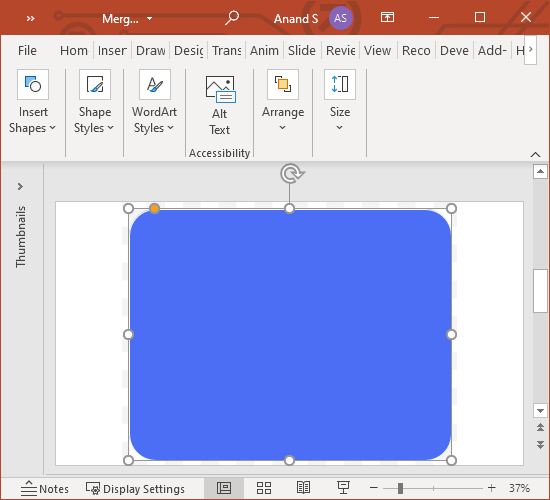
Next, let’s create the body. We’ll create a rounded rectangle that matches the bottom half of the body, another that matches the top half of the body, and intersect them, like this:
Then, draw a large circle around the head and subtract it from the body, like this:
Finally, copy all these shapes over the card boundary on the next page. Select the card boundary first. Then select these copied shapes (3 address lines, head, and bust). Select Shape Format > Merge Shapes > Subtract.
With that, we have a single shape that contains the entire address card. The white areas are transparent.
You can download the Merge-Shapes.pptx file below with each of the steps.
The World Mosquito Program (WMP) modifies mosquitoes with a bacteria — Wolbachia. This reduces their ability to carry deadly viruses. (It makes me perversely happy that we’re infecting mosquitoes now 😉.)
Modifying mosquitoes is an expensive process. With a limited set of “good mosquitoes”, it is critical to find the best release points that will help them replicate rapidly.
But planning the release points took weeks of manual effort. It involved ground personnel going through several iterations.
So our team took high-resolution satellite images, figured out the building density, estimated population density based on that, and generated a release plan. This model is 70% more accurate and reduced the time from 3 weeks to 2 hours.
Some actors form cliques — working only with each other
Often, comedians are the bridge between cliques
It’s interesting to see how actors from one clique can connect to another
Creating the storyline
When exploring of actors’ connections, we found a clearly delineated network structure.
The group of densely clustered actors is the Bollywood-Tollywood-Mollywood-Kollywood nexus. It appears disconnected from the Hollywood cluster. (We excluded anyone who hadn’t acted together in at least 4 films.)
We realized that it’s tough for someone in Bollywood to connect to Hollywood. Maybe that could be the plot? For example, what if Amitabh Bachchan wants to act with Metryl Streep?
But this isn’t an interesting story. So we asked:
Who is the most desirable heroine in Hollywood? Our guess was Angelina Jolie
The morning of the hackathon was spent finalizing the screenplay and dialogues, written on Dropbox Paper.
CUT TO:
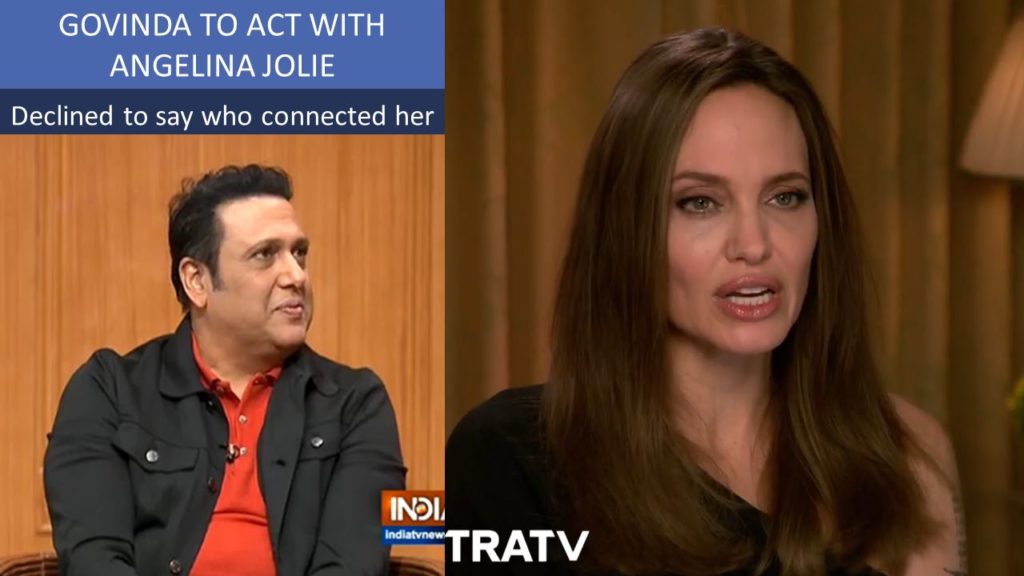
- Video of Govinda "declining James Cameron's Avatar" on Aap Ki Adalat
- Niyas: On July 29, 2019, Govinda announces he declined a role in Avatar.
- Video: https://youtu.be/NyFF18a7e-Y
- Picture: https://twitter.com/mohan_rajkeshav/status/1156148768049262592
CUT TO:
- Visual: Show an interview video of Govinda and of Angelina
- Niyas: Today, he announced his next film with Angelina Jolie.
A “close friend” connected them, but didn't say who.
- Kishore: Who is this close friend? Why is he not naming them?
- Video: https://youtu.be/NyFF18a7e-Y (Govinda)
- Video: https://youtu.be/JNrH1W7aKc8 (Angelina)
CUT TO:
- Visual: Show the top 8 heroines Govinda has acted with.
Visualize this data with animation.
One option is to have Govinda’s pic in the center,
and have each of these 9 heroine’s images appear around him
as a circle, with the number of pictures in a link.
Or as the inverse link distance (e.g. 11 is closest)
11 Neelam Kothari
10 Kimi Katkar
10 Karisma Kapoor
9 Raveena Tandon
9 Farha Naaz
8 Juhi Chawla
6 Anita Raj
6 Mandakini
5 Shilpa Shetty Kundra
- Niyas: Maybe it’s because it’s one of his heroines?
He’s mostly acted with Neelam, Kimi and Karishma.
But none of them has acted with any Hollywood actor.
MORPH TO:
- Visual: Add these actors with pics to the same visual,
but clearly differentiated by gender. Also add their names.
22 Shakti Kapoor
18 Kader Khan
13 Gulshan Grover
9 Anupam Kher
8 Dharmendra
7 Johnny Lever
6 Sadashiv Amrapurkar
6 Vikas Anand
6 Sanjay Dutt
6 Prem Chopra
6 Asrani
- Kishore: So maybe this “close friend” is a male actor?
- Niyas: He’s acted with Gulshan Grover, Kader Khan and Shakti Kapoor a lot.
- Kishore: Shakti Kapoor is practically his boyfriend!
MORPH TO:
- Visual: Zoom into Gulshan Grover and Anupam Kher.
Build a network of film posters around them
with their Hollywood films (max 2-4)
- Anupam Kher
- Bend It Like Beckham
- Lust & Caution
- Silver Linings Playbook
- A Family Man
- Gulshan Grover
- Prisoners of the Sun
- The Second Jungle Book
- Marigold
- Monsoon
- Niyas: Gulshan Grover and Anupam Kher have acted in a number of Hollywood films
- Kishore: But have they acted with Angelina Jolie?
- Niyas: No, never with Angelina Jolie.
- Kishore: But what if any of them connected him to someone who connected him to Angelina?
CUT TO:
- Visual: Show Angelina Jolie with ~100 actors around her. Highlight the following:
- Jack Black, 3
- Dustin Hoffman, 3
- Giovanni Ribisi, 2
- Robert De Niro, 2
- Brad Pitt, 2
- Elle Fanning, 2
- Bryan Cranston, 2
- 92 other actors with only 1 film each
- Highlight Irrfan Khan — A Mighty Heart
- Niyas: Angelina Jolie has acted with less than 100 actors.
Dustin Hoffman and Jack Black, mostly.
Only one of them is an Indian actor: Irrfan Khan
MORPH TO:
- Visual: Expand the connection between Angelina and Irrfan
- Kishore: So, Govinda needs to connect to Irrfan Khan somehow.
MORPH TO:
- Visual: Connect Govinda to Irrfan Khan via
- Gulshan Grover via Knock Out
- Sanjay Dutt via Knock Out
- Tabu via Saajan Chale Sasural, Dil Ne Phir Yaad Kiya (and 2 others)
- Niyas: That should be easy.
Gulshan Grover and Irrfan Khan have acted together in Knock Out.
So has Sanjay Dutt.
But Tabu will be a better option. Govinda and Irrfan Khan have acted with her in 4 movies each.
MORPH TO:
- Visual: Show path from Govinda to Tabu to Irrfan to Angelina.
- Kishore: Then, Govinda must have connected to Tabu
who introduced him to Irrfan Khan,
who in turn connected him with Angelina Jolie.
Create the video
Anand and Niyas created the visuals on PowerPoint, collaborating on Dropbox.