Web lookup using Google Spreadsheets
I’d written earlier about Web lookup in Excel. I showed an example how you could create a movie wishlist that showed the links to the torrents from Mininova.
You can do that even easier on Google Spreadsheets. It has 4 functions that let you import external data:
- =importData(“URL of CSV or TSV file”).
Imports a comma-separated or tab-separated file. - =importFeed(URL).vLets you import any Atom or RSS feed.
- =importHtml(URL, “list” | “table”, index).
Imports a table or list from any web page. - =importXML(“URL”,”query”).
Imports anything from any web page using XPath.
Firstly, you can see straight off why it’s easy to view RSS feeds in Google Spreadsheets. Just use the importFeed function straight away. So, for example, if I wanted to track all 8GB iPods on Google Base, I can import its feed in Google Spreadsheets.
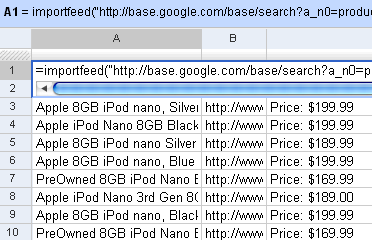
This automatically creates a list of the latest 8GB iPods.
Incidentally, the “Price” column doesn’t appear automatically. It’s a part of the description. But it’s quite easy to get the price using the standard Excel functions. Let’s say the description is in cell C1. =MID(C1, FIND("Price", C1), 20) gets you the 20 characters starting from “Price”. Then you can sort and play around as usual.
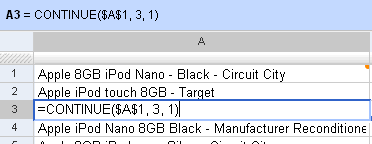
The other powerful thing about Google Spreadsheets is the CONTINUE function. The importFeed function creates a multi-dimensional array. You can extract any cell from the array (for example, row 3, column 2 from cell C1) using CONTINUE(C1, 3, 2). So you can just pick up the title and description, or only alternate rows, or put all rows and columns in a single column — whatever.
The most versatile of the import functions is the importXML function. It lets you import any URL (including an RSS feed), filtering only the XPath you need. As I mentioned earlier, you can scrape any site using XPath.
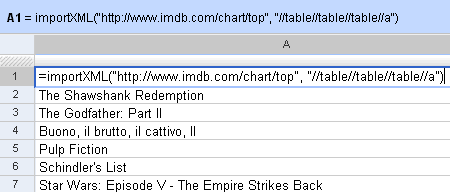
For example, =importXML("http://www.imdb.com/chart/top", "//table//table//table//a") imports the top 250 movies from the IMDb Top 250. the second parameter says, get all links (a) inside a table inside a table inside a table. This populates a list with the entire Top 250.
Now, against each of these, we could get a feed of Mininova’s torrents. Mininova’s RSS URL is http://www.mininova.org/rss/search_string. So, in cell B1, I can get a torrent for the cell A1 (The Godfather) using the importFeed function. (Note: you need to replace spaces with a + symbol. These functions don’t like invalid URLs.).
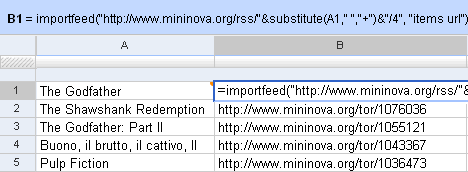
Just copy this formula down to get a torrent against each of the IMDb Top 250 movies!
Check out the sheet I’ve created. (You need a Google account to see the sheet. If you don’t want have one, you can view the sheet.)
Now, that’s still not the best of it. You can extract this file as an RSS feed! Google lets you publish your sheets as HTML, PDF, Text, XLS, etc. and RSS and Atom are included as well. Here’s the RSS feed for my sheet above.
Think about it. We now have an application that sucks in data from a web page, does a web-based vlookup on another service, and returns the results as an RSS feed!
There are only two catches to this. The first is that Google has restricted us to 50 import functions per sheet. So you can’t really have the IMDb Top 250 populated here — only the top 49. The second is that the spreadsheet updates only when you open it again. So it’s not really a dynamically updating feed. You need to open the spreadsheet to refresh it.
But if you really wanted these things, there’s always Yahoo! Pipes.