Hindi songs 1995s
Here is the background music from some Hindi songs between 1995-1999. Can you guess which movie they are from?
Don’t worry about the spelling. Just spell it like it sounds, and the box will turn green.
Here is the background music from some Hindi songs between 1995-1999. Can you guess which movie they are from?
Don’t worry about the spelling. Just spell it like it sounds, and the box will turn green.
1.5 million internal e-mails of Enron were released after it collapsed, to help figure out why. The UC Berkeley Enron Email Analysis Project has some links analysing these emails. Check out the visual analysis.
I talked about my approach for multicriteria decision-making, and mentioned that it was fundamentally flawed. Here’s why.
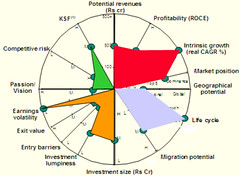
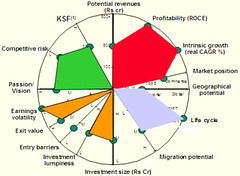
The charts above compared two industries. The bigger the area, the more favourable the industry. The underlying assumptions being:
In this particular example, I know for a fact that both these assumptions are invalid. And in every case I used this methodology, the assumptions fail.
You won’t draw the criteria to scale. We used revenues and growth as two parameters, and marked each industry as high, medium or low. The scale for revenue was Rs 100 cr, Rs 500 cr and over Rs 500 cr. The scale for growth was <5%, 5-10%, >10%. We picked this scale in order to fit the range well on these graphs. Not because Rs 100 cr of revenue was worth about the same as 5% of growth. And yet, that’s the implicit trade-off this graph is asking us to make.
We also had very qualitative criteria, like “Capability” (KSF), and they were compared head-on with growth and revenue. Using qualitiative criteria is not a bad thing. But when the visual makes you trade-off capability against Rs 500 cr of revenue, I feel queasy.
You will miss important criteria. Usually, the process for identifying criteria is bad. “Think of every criteria you can” was our standard approach. In this instance, in our first iteration, we had a dozen parameters. We showed it to the client. They said, “Look, our Chairman likes these industries a lot. He doesn’t like that bunch. We’re much more likely to focus on the ones he likes.” And that’s absolutely important! We ended up adding a “Passion / vision” based on the fit with the company’s existing businesses, and that proved the deciding factor.
Another time, I built an entire model on which project to outsource based on 10 parameters. (It was everything I could think of at the time.) The one that I missed was, “When is the project starting?”. It turned out that this was the most important criteria. In fact, it was the only important criterion. If I’d simply said, all projects starting after 1-June-2006 can be outsourced, I would’ve been 90% right.
You’ll keep the irrelevant parameters. This is the worst of all. Even after we learnt which the important criteria were, we didn’t throw away the useless parameters. We never throw away hours of work, even if it’s useless. So the model keeps bloating, and the irrelevant criteria influenced the shape of the graph more than the relevant ones.
Another problem is that this methodology cannot answer questions concisely.
“Why did you knock off Industry X?”
“Oh, because on a cumulative score against revenue, growth, lifecycle, capability, passion and 10 others, it scores less than 45 points.”
A good answer should be short. For GE, it would be “You’ll never be number one.” For HP, once, it would’ve been “It’s not where we can excel technically.” For Warren Buffet, it may be “I don’t understand the business.”
After these experiences, and based on hindsight, I’ve come to believe the following about MCDM (multi-criteria decision making):
I’ll let you read up on fast and frugal heuristics. I’m convinced it’s the best way to make decisions based on multiple criteria in the scenarios I’ve worked on.
These are pavement drawings. They are NOT 3D objects. But it’s hard to believe. (Even the shadows are perfect.) See more at Julian Beaver’s site.



Here is the background music from some Hindi songs from the 2000s. Can you guess which movie they are from?
Don’t worry about the spelling. Just spell it like it sounds, and the box will turn green.
When I wrote my Tamil song lyrics quizzes, I had two problems:
I overcame the first using a Tamil transliterator. I write in English, and you see it in Tamil.
The problem of ந vs ன was simple. ந occurs as the first letter of a word, and just before த. Nowhere else. (Is this always true?)
But ர vs ற can’t be solved except through experience, and I’m short of that. So, rather than bother my family with every quiz, I used the wisdom of crowds. I googled both spellings of the word. The correct spelling has more Google hits than the incorrect one.
I did this so often, I made a Google gadget out of it.
Just type the word in English, click ‘Search’, and my gadget will search in tamil. It’s amazing how much stuff there is in Tamil on the Web, from song lyrics to texts (thirukkuraL, for example).
You can add this gadget to:
Here’s the transliteration table:
| Tamil | English |
|---|---|
| அ | a |
| ஆ | A or aa |
| இ | i |
| ஈ | I or ee |
| உ | u |
| ஊ | U or oo |
| எ | e |
| ஏ | E |
| ஐ | ai |
| ஒ | o |
| ஓ | O |
| ஔ | au |
| க | k or g |
| ங | n |
| ச | ch or s |
| ஜ | j |
| ஞ | n |
| ட | t or d |
| ண | N |
| த | th or dh |
| ந | n |
| ப | p or b |
| ம | m |
| ய | y |
| ர | r |
| ல | l |
| வ | v |
| ழ | zh |
| ள | L |
| ற | R |
| ஷ | sh |
| ஸ | S |
| ஹ | h |
Video of Guy Kawasaki’s talk on The Art of the Start at TiECon 2006.
It’s informative, even if you don’t want to start a venture, but I didn’t know Guy was such a funny speaker! He begins with:
Early in my career, I sat through many keynote speeches — at Comdex, at Mac Road Expo. I saw many many hi-tech CEOs speak, and I have to tell you, one thing I noticed is they pretty much sucked as speakers. And the second thing that I figured out sitting in these audiences of sucky keynotes is that if there’s anything that’s worse than a CEO who sucks as a speaker, it’s a CEO who sucks as a speaker and you have no idea how much longer he or she will suck! And so, I have adopted the top 10 format for all of my speeches. This way, if you think I suck, at least you can track progress through my speech.
Towards then end, when he’s run well over time…
What are you going to do? Not invite me again?
He gets dragged off the stage.
Have a look at this infinite depth painting. You can zoom in forever. At some point, you realise, you’re back where you’re started. Almost like going around in circles, except that you’re zooming in.
Jason Kottke finds interesting code search hacks, ranging from the WinZip key generation algorithm to programmers who want a new job.
I had to screen resumes from a leading MBA school. I’m lazy, and there were hundreds of CVs. So after procrastinating until this morning, I decided on 2 principles:
The CVs were in a single PDF file. I saved it as text (it shrunk from 66MB to 1.6MB without the photos). Then I wrote a Perl program to filter CVs by keywords. We were looking for people with an interest and/or experience in IT consulting, so I picked “technology”, “consulting”, “SAP”, “IBM”, “Accenture”, “Deloitte”, etc.
Anyone without these keywords would fall out of the list. This eliminated 75% of the crowd. But since I didn’t want to read the rest, I used my favourite text-analysis technique: concordance. I extracted 3 words on either side of each keywords, and just read those. It was easy to see who’d “worked with suppliers like IBM” as opposed to who’d worked at IBM.
That’s it! I managed to cut the list down to 10%. Better yet, I also had a preference ranking. People with multiple keywords ranked higher than those with fewer keywords. And all this took little more than my train ride to office.
I can see this going to the next level. It’s easy to write a customised rejection letter, depending on which keywords are missing for each person.
Now, if it’s this easy to filter resumes, I can see every organisation do it in a few years. Which means, you need to write resumes for machines as well, not just for humans! For example, on my next CV, I’ll make sure I include the words “Boston Consulting Group” as well as “BCG” — just in case the software searches for only one of those keywords. Further, I’ll make sure I avoid spelling mistakes!