AI Coding Agent Subscription ROI
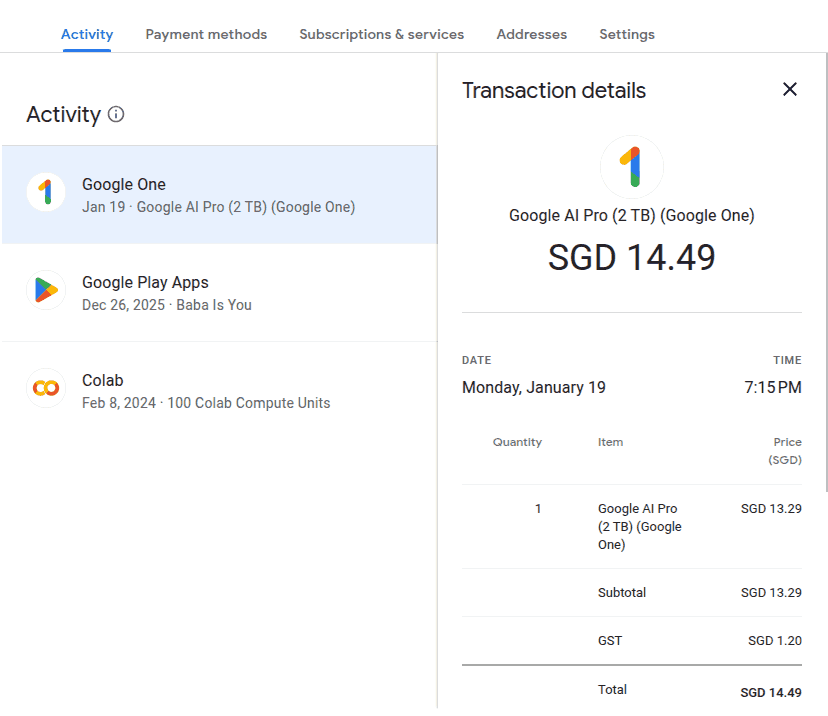
I ran npx -y ccusage monthly --compact to get the following break-up of my AI coding agent costs. Month Codex Claude 2025-09 $37.47 $2.29 2025-10 $106.79 $9.13 2025-11 $100.35 $14.24 2025-12 $240.69 $24.88 2026-01 $100.89 $20.28 2026-02 $323.21 $29.46 2026-03 $1996.32 $134.87 2026-04 $401.36 $47.07 2026-05 $378.20 $45.13 This shows the ROI of my $20 subscriptions to each. I get ~$35 worth of API calls for my $20 Claude Pro subscription and ~$400 of API calls for my $20 ChatGPT Plus subscription (on top of my ChatGPT chats.) ...